
How to Deploy DeepSeek R1 on DigitalOcean: Three Approaches, Three Scenarios
This article compares three ways to deploy DeepSeek R1, a cost-effective large language model (LLM), on DigitalOcean. Each approach offers distinct trade-offs in setup complexity, security, fine-tuning, and system-level customization. By the end of this guide, you’ll know which method best matches your technical experience and project requirements.
Overview
DeepSeek R1 is a versatile LLM for text generation, Q&A, and chatbot development. On DigitalOcean, you can deploy DeepSeek R1 in one of three ways:
-
Approach A: GenAI Platform (Serverless)
A platform-based solution that minimizes DevOps overhead and delivers quick results, but doesn’t support native fine-tuning. -
Approach B: DigitalOcean + Hugging Face Generative Service (IaaS)
Offers a prebuilt Docker environment and API token, supports multiple containers on a GPU droplet, and allows training or fine-tuning. -
Approach C: GPU + Ollama (IaaS)
Provides complete control over the OS, security configurations, and model fine-tuning, but comes with higher complexity.
Cost Considerations
Approach A: GenAI Platform (Serverless)
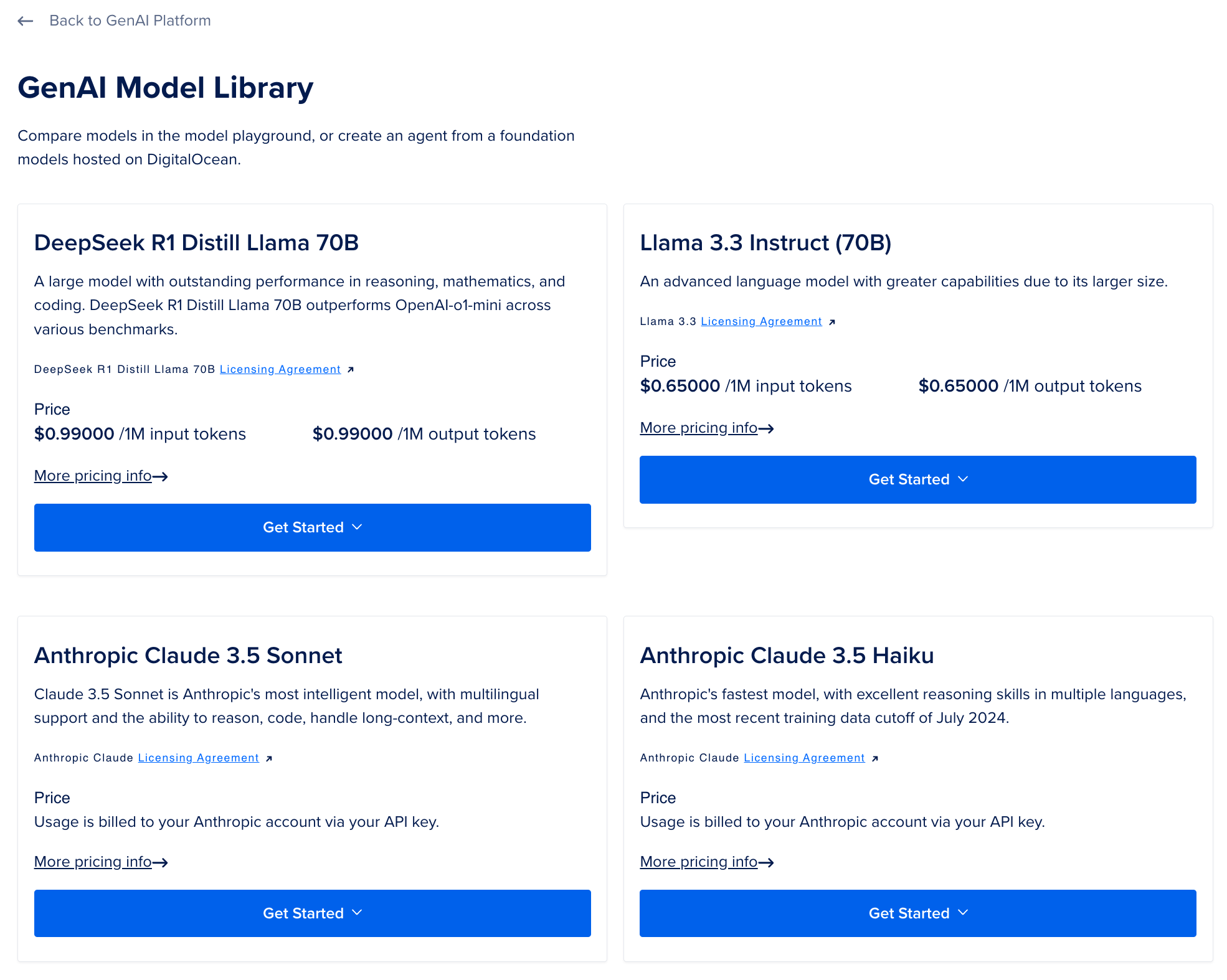
The DigitalOcean GenAI Platform uses a usage-based pricing model:
- Token-Based Billing: You pay for both input and output tokens (tracked per thousand tokens, displayed per million tokens).
- Open-Source Models: For instance, DeepSeek-R1-distill-llama-70B is $0.99 per million tokens. Lower-priced models start at $0.198 per million tokens.
- Commercial Models: If you bring your own API token (e.g., Anthropic), you follow the provider’s rates.
- Knowledge Bases: Additional fees for indexing tokens and vector storage.
- Guardrails: $3.00 per million tokens if you enable jailbreak or content moderation.
- Functions: Billed under DigitalOcean Functions pricing.
Playground Limit: The GenAI playground is free but limited to 10,000 tokens per day, per team (covering both input and output).
Approach B & C: GPU Droplets
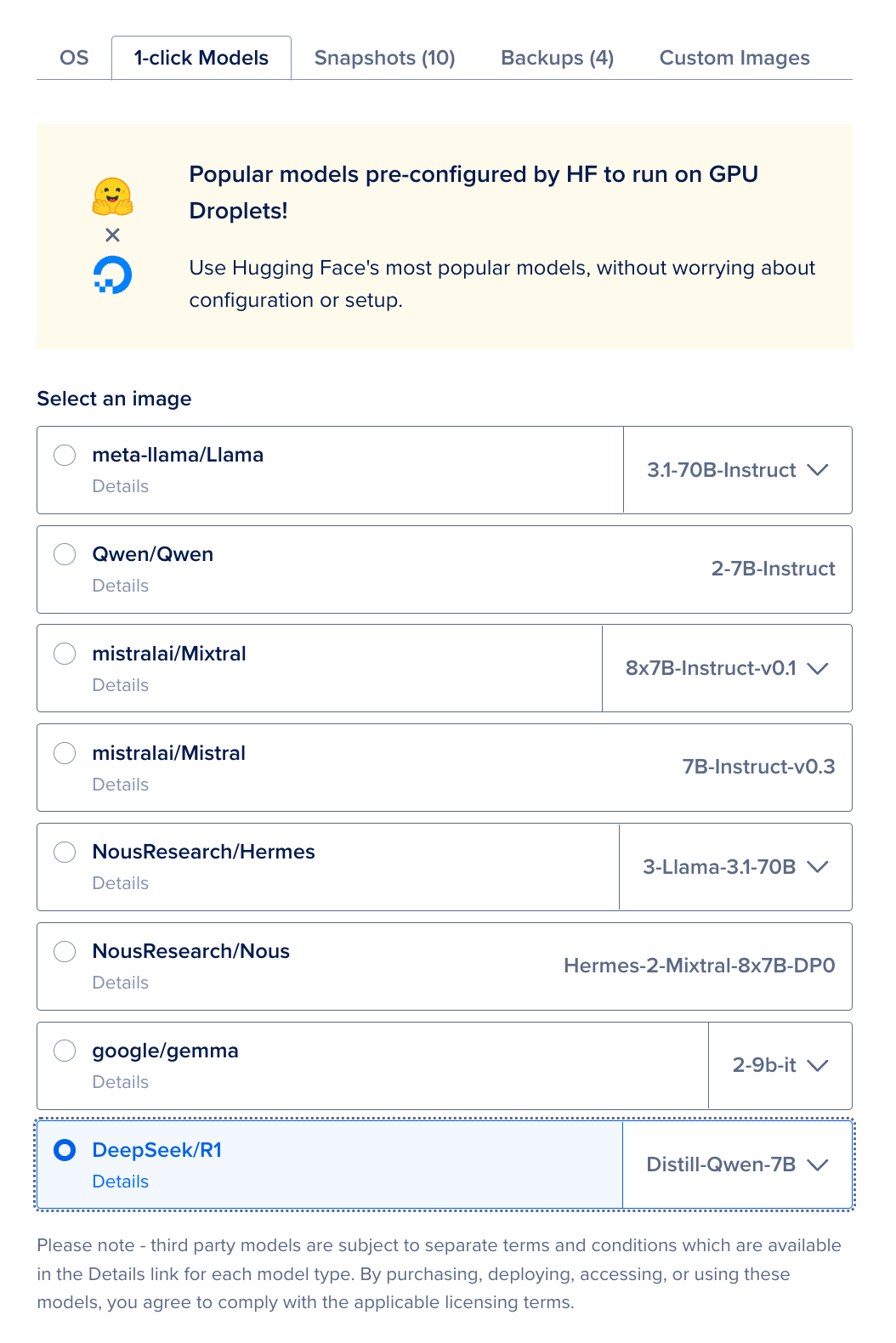
For Approach B (HUGS on IaaS) and Approach C (Ollama on IaaS), you’ll provision a GPU droplet. Refer to Announcing GPU Droplets for current pricing. At publication:
- Starting at $2.99/GPU/hr on-demand (subject to change).
- Additional fees (like data egress or storage) may apply.
- You’re responsible for OS-level security, scaling, and patches.
Security and Maintenance
-
Approach A (GenAI Serverless)
- Security patches and maintenance are handled automatically.
- Optional guardrails or KBs incur token-based charges.
-
Approach B (HUGS on a GPU Droplet)
- You manage OS security, Docker environments, and firewall rules.
- The default token-based authentication is provided for the LLM endpoint.
-
Approach C (Ollama on a GPU Droplet)
- You take on the highest level of control and responsibility: OS security, firewall, usage monitoring.
- Ideal for compliance or custom configurations but requires more DevOps work.
Performance Benchmarks?
No official speed metrics or SLAs are currently published. Performance depends on GPU size, data load, and specific workflows. If you need help optimizing performance, reach out to our solution architects. We may share future articles on benchmarking techniques.
Approach A: GenAI Platform (Serverless)
Use Approach A for a fully managed DeepSeek R1 deployment without provisioning GPU droplets or handling OS tasks. You can quickly create a chatbot, Q&A flow, or basic RAG setup through a user-friendly UI.
When to Choose Approach A
- You have limited DevOps experience or prefer not to manage servers.
- You need a quick AI assistant (e.g., a WordPress plugin or FAQ bot).
- You don’t plan to train or fine-tune the model with private data.
Example Scenario: Chelsea’s Local Café Blog

Chelsea hosts a WordPress blog for her café, posting menu updates and community events. She’s comfortable with site hosting but not OS administration:
- She wants a chatbot to answer questions about open hours, menu specials, or local events.
- Guardrails can be added later if she faces problematic content.
- The GenAI Platform demands minimal server management, making it an easy choice.
Not Ideal If…
- You need fine-tuning or domain-specific training.
- You must meet strict security needs (private networking, advanced OS rules).
- You plan to run multiple microservices or intensive tasks on a single server.
Approach B: DigitalOcean + Hugging Face Generative Service (HUGS)
Approach B suits developers who want a GPU droplet-based solution with HUGS, offering partial sysadmin freedoms (multi-container) and a straightforward API token. It supports training or fine-tuning locally.
When to Choose Approach B
- You want a quicker path to an AI endpoint than a fully manual approach.
- You aim to do some training or fine-tuning on the same GPU droplet.
- You know Docker basics and don’t mind partial server administration.
Example Scenario: CHFB Labs

CHFB Labs builds fast Proofs of Concept for clients:
- Some clients need domain-specific training or partial fine-tuning.
- Extra Docker containers (e.g., staging or logging) can run on the same droplet.
- A default access token is included, avoiding custom auth code.
Not Ideal If…
- You want a serverless approach (Approach A is simpler).
- You require advanced OS-level tweaks (e.g., kernel modules).
- You prefer a completely manual pipeline with zero pre-configuration.
Approach C: GPU + Ollama
Use Approach C when you need full control over your GPU droplet. You can configure OS security, implement custom domain training, and create your own endpoints, albeit with higher DevOps demands.
When to Choose Approach C
- You want to manage the OS, Docker, or orchestrators manually.
- You need strict compliance or advanced custom rules (firewalls, specialized networking).
- You plan to fine-tune DeepSeek R1 or run large-scale tasks.
Example Scenario: Mosaic Solutions

Mosaic Solutions provides enterprise analytics:
- They store sensitive data and require encryption or specialized tooling.
- They install Ollama directly to manage exposure of DeepSeek R1.
- They handle OS monitoring, usage logs, and custom performance tuning.
Not Ideal If…
- You dislike DevOps tasks or can’t manage OS-level security.
- You want a single-click or minimal-effort deployment.
- You only need a small chatbot with limited usage.
Comparison
Use the table below to compare the three approaches:
| Category | Approach A (GenAI Serverless) | Approach B (DO + HUGS, IaaS) | Approach C (GPU + Ollama, IaaS) |
|---|---|---|---|
| SysAdmin Knowledge | Minimal — fully managed UI, no server config | Medium — Docker-based GPU droplet, partial sysadmin | High — full OS & GPU management, custom security, etc. |
| Flexibility | Medium — built-in RAG, no fine-tuning | High — multi-container usage, optional training/fine-tuning on GPU | High — custom OS, advanced security, domain-specific fine-tuning |
| Setup Complexity | Low — no droplet provisioning | Medium — create GPU droplet, launch HUGS container, handle Docker | High — manual environment config, security, scaling |
| Security / API | Managed guardrails, limited endpoint exposure | Token-based by default; can run more services on the same droplet if needed | DIY — create auth keys, firewall rules, usage monitoring |
| Fine-Tuning | No | Yes — integrated via training scripts | Yes — fully controlled environment for domain training |
| Best For | Non-technical users, quick AI setups, zero DevOps overhead | Teams needing quick PoCs, multi-app on GPU droplet, partial training | DevOps-savvy teams, specialized tasks, compliance, domain-specific solutions |
| Not Ideal If… | You need fine-tuning or OS-level custom, want multi-LLM | You want a fully serverless approach or advanced OS modifications | You want a quick setup, have no DevOps staff, only need a small chatbot |
Conclusion
Your choice of deployment method depends on how much control you need, whether you want fine-tuning, and how comfortable you are with GPU resource management:
-
Approach A (GenAI Serverless)
- Easiest to begin, no GPU droplet required.
- Limited customization, no fine-tuning.
- Ideal for a basic chatbot or Q&A (like a WordPress plugin).
-
Approach B (DigitalOcean + HUGS, IaaS)
- Moderate complexity, a prebuilt Docker environment on a GPU droplet.
- Partial sysadmin for multiple services, supports local fine-tuning.
- A balanced option between convenience and flexibility.
-
Approach C (GPU + Ollama, IaaS)
- Highest control: OS-level security, large-scale tasks, advanced training.
- Suitable for compliance or specialized pipelines.
- Demands significant DevOps expertise.
Next Steps
- Approach A Tutorial: Learn how to set up a chatbot using the GenAI Platform in minutes.
- Approach B Guide: Spin up a GPU droplet with HUGS, secure it with a token, and integrate training or fine-tuning.
- Approach C Article: Explore complete GPU droplet control via Ollama, create custom inference endpoints, and handle domain-specific training.
Where to Go from Here
- View GenAI Platform Pricing for Approach A’s token-based billing.
- Check out Announcing GPU Droplets for GPU droplet costs (Approach B & C).
- We don’t publish official performance benchmarks at this time. For optimization help, contact our solution architects or watch for future articles on performance testing.
- Explore the DigitalOcean Community for tutorials on droplet management, Docker usage, or other advanced pipelines.
Happy deploying and fine-tuning!


