
利益揭露:我是 DigitalOcean 的 Solutions Architect,所以文中提到 DigitalOcean 產品時,是「業內人的觀點」而非中立第三方——這些地方我都會明確標示,其餘分析則盡量保持廠商中立。以下皆為個人觀點。
前言
剛接觸生產級 LLM 工作的工程團隊常見一種模式:他們從排行榜頂端挑一個模型、整合進系統,然後接下來好幾個月都在想辦法降低帳單。這個順序是反過來的。
模型選型——不是基礎設施、不是提示最佳化、也不是批次處理策略——才是 GenAI 部署中對品質與成本最大的單一槓桿。在一個簡單的分類任務上,Claude Sonnet 4.6 與 Claude Haiku 4.5 的價格差距大約是 12 倍。如果 Haiku 在你的特定任務上能產出同等品質,那麼你每多用一天 Sonnet,就是多付了 12 倍。
問題在於,大多數團隊挑模型的方式是錯的:他們看基準測試排行榜,找出分數最高的那個,然後就上線了。本文會說明為什麼這種做法會得到次佳結果——以及正確的評測流程實際上是什麼樣子,並透過四個不同的使用情境類別來闡述。
重點摘要
- 模型選型——而非硬體——是 GenAI 成本與品質兩者最大的單一槓桿。
- 先建立你的準確度下限,然後挑出能跨過這條線的最小模型——而不是排行榜頂端那一個。
- 針對每種任務使用正確的指標:翻譯用 COMET(不是 BLEU)、RAG 用忠實度(groundedness)、程式碼用私有的評測框架、面向客戶的對話則用 TTFT。
- 基準測試是篩選用的過濾器,不是最終判決:MMLU 已飽和、SWE-bench Verified 容易受污染影響(約 70% 對比較難的 Pro 測試集約 23%),而同一個模型在不同評測框架下分數可能相差 10–15%。
- 你自己的資料才是唯一具權威性的訊號——而且較小的專才在自己的主場上,經常能擊敗較大的通才。
選型框架:先定準確度下限,再談成本
模型選型正確的心智模型不是「找出最好的模型」——而是 「先找出你任務的準確度下限,再找出能跨過這條線的最小模型」。
把它想成在雇用承包商。你不會請結構技師來重新粉刷一個房間——你會請技能與工作相稱的人。如果你的任務需要在行銷文案中拿捏細膩的語氣,你大概需要那位資深技師。如果任務只是從文件中擷取一個日期,那麼便宜 80% 的菜鳥也綽綽有餘。錯誤不一定在於雇錯了人——而是在沒檢查便宜的人是否也能勝任的情況下,就雇了那個貴的。
把候選模型倒過你的準確度下限,留下能通過的最小那一個。
流程是這樣運作的:
- 定義你的準確度下限——在對你的使用情境重要的特定指標上,最低可接受的表現是什麼?不是「越好越好」,而是低於這個門檻產品就壞掉的那條實際界線。
- 用你自己的資料做評測——使用你生產環境分布中具代表性的樣本,而不是基準測試的分布。
- 找出能跨過你下限的最小模型——從小開始往上試。通過你評測的模型都是候選者;最便宜的候選者勝出。
- 在模型更新時重新檢視——供應商發布新模型的頻率很高。六個月前能跨過你下限的最便宜模型,可能已被新的層級超車。
本文每一個論點,都是把同樣的邏輯套用到四個特定的使用情境類別上。
翻譯:指標錯配的案例研究
翻譯是個實用的案例研究,因為它暴露了許多團隊評測 LLM 時的一個根本缺陷:容易計算的指標,往往沒在衡量真正重要的東西。
BLEU 對比 COMET:為什麼標準指標會說謊
BLEU——傳統的機器翻譯指標——計算模型輸出與參考譯文之間的 n-gram 重疊。它速度快、具確定性、容易計算。但對任何需要細膩拿捏的東西來說,它也是個很差的品質預測指標。
把 BLEU 想成靠數一首詩押了幾個韻來評斷它。一首押韻完美卻言之無物的詩會得高分;一首捕捉到你前所未見的情感、卻打破了韻腳的詩則會得低分。這個指標最佳化的是錯的東西。
COMET(Crosslingual Optimized Metric for Evaluation of Translation,翻譯評估跨語言最佳化指標)是一個以人類評斷訓練出來的神經網路指標。它與真實人類讀者評斷翻譯品質的方式相關性高得多——而且關鍵在於,它能讓 BLEU 的排名翻轉。一個在 BLEU 上得分較高的模型,有時在 COMET 上反而得分較低,因為人類眼中的品質與 n-gram 重疊無關。
對任何認真的翻譯評測來說,COMET 應該是你的主要指標,BLEU 則只留作健全性檢查(sanity check)。
DeepL 對比 LLM:對大量工作而言,速度是決定性變數
對高流量翻譯而言,DeepL 與 LLM 之間的速度差距是決定性的。Google 的 Neural Machine Translation 引擎能在毫秒內交出結果——比 LLM 快上達 20 倍。DeepL 在高吞吐量下表現相當。對於每小時要處理數千個片段的大量文件翻譯流程來說,那個速度差距會直接反映在基礎設施成本上。
大量翻譯:NMT 是快速壓印機,LLM 是細心的謄寫員——比較慢,但更懂細膩之處。
LLM 則有不同的特性側寫:它們在長篇上下文、慣用語、低資源語言,以及語氣很重要、對品牌敏感的文案上勝出。Lokalise 的盲測研究比較了五個引擎在英文 → 德文、波蘭文與俄文上的表現——由母語人士以成對比較方式評斷——發現 Claude 3.5 以 78% 拿下最高的「良好」評比,勝過 GPT-4o 以及所有三個受測的 NMT 引擎。
Rapidata 走得更遠:他們用超過 51,000 名母語人士的回饋,比較了 DeepL 與 DeepSeek-R1、Llama 及 Mixtral,該資料集現已在 Hugging Face 上公開。結論很微妙——在所有語言對與內容類型上,沒有任何一類能全面勝出。
2026 年在地化產業的共識:
| 使用情境 | 建議做法 |
|---|---|
| 高流量、重複性的文件(合約、產品說明) | 以 DeepL 或 Google NMT 為主引擎 |
| 行銷文案、品牌口吻、對語氣敏感的內容 | 用 LLM(Claude)做最終調整 |
| 低資源語言對 | 微調後的 NLLB-200 3.3B 經常勝過通用的 7-8B LLM |
| 特定領域術語(法律、醫療) | 在領域語料上微調的模型 |
| 大規模即時、面向使用者的翻譯 | NMT;LLM 對同步 UX 來說太慢 |
關鍵洞見:對低資源語言與特定領域的語言對而言,微調後的 NLLB-200 3.3B——一個 33 億參數的模型——仍然勝過通用的 7-8B LLM。較小的專才在自己的主場上擊敗了較大的通才。
AI 在地化的主要阻礙不是技術——而是信任。 後編輯(post-editing)工作流程之所以存在,正是因為生產團隊還沒準備好在沒有人類查核點的情況下發布 LLM 的輸出,無論基準測試分數多高。評測方法必須把這一點納入考量:問題不只是「這個輸出分數高不高?」,而是「母語人士會不會在不經審查的情況下信任它?」
RAG 流程:評測完整的鏈路,而非孤立地評測模型
RAG(Retrieval-Augmented Generation,檢索增強生成)的評測,正是團隊最常犯下「只評測生成步驟」這個錯誤的地方。完整的流程有三個品質可能劣化的環節:
- 嵌入品質——檢索系統有沒有撈出正確的片段?
- 檢索精確度——前 k 名的結果是否真的相關?
- 生成忠實度——模型有沒有緊扣檢索到的上下文,還是它在產生幻覺?
第三個指標——忠實度(groundedness)——是 RAG 最主要的品質訊號。一個能準確摘要檢索上下文的模型很有價值;一個會自信地產出看似合理卻錯誤、且不在檢索上下文中的答案的模型則很危險,無論它的基準測試分數有多好。
把評測 RAG 流程想成評測一位研究助理。你不只是測他能不能寫得清楚——你還要測他是否只引用你給他的文件裡實際存在的內容,而不會虛構出支持自己答案的來源。
RAG 模型選型的實務做法:
- 把檢索品質(正確的內容有沒有回來?)與生成品質(答案是否忠實於回來的內容?)分開評測
- 在你知道正確答案(ground truth)的保留樣本上,量測幻覺率
- 對穩定上下文(系統提示 + RAG 模板)做提示快取,是最主要的成本槓桿——一個快取做得好的 RAG 流程,會有 70-80% 的輸入 token 從快取供應,價格只要基礎輸入價的 10%。模型與提示結構要同時選定;你無法把快取硬塞進一個結構糟糕的提示裡。
對大多數 RAG 使用情境來說,中階模型(Claude Sonnet、GPT-4o mini)的表現,會優於外界預期的、與前沿模型之間的品質落差,因為只要提示得當,忠實度是一種可控的行為——它不需要最頂級的模型智慧。把評測時間花在量測忠實度上,而不是去跑原始智慧的基準測試。
程式碼生成:為什麼私有程式碼庫的表現總是不如基準測試
程式碼生成代理(agent)的標竿基準測試是 SWE-bench——具體來說是用 SWE-bench Verified(500 個經人工驗證的 Python 任務)做初步篩選,並且越來越常用 SWE-bench Pro 取得更難的訊號。
以下是重要的背景:
SWE-bench Verified 有污染問題。 OpenAI 在 2026 年 2 月停止以它作為對照回報,因為稽核發現許多基準任務的解答可以從議題文字(issue text)洩漏出來,而且模型高達 76% 的時候會從訓練資料中回想起檔案路徑。頂尖模型在 Verified 上得分 70% 以上。但在 SWE-bench Pro——一個由 Scale AI 打造、抗污染的替代測試集——上,頂尖模型大約只得 23%。這個落差告訴你一件重要的事:排行榜實際上在衡量什麼。
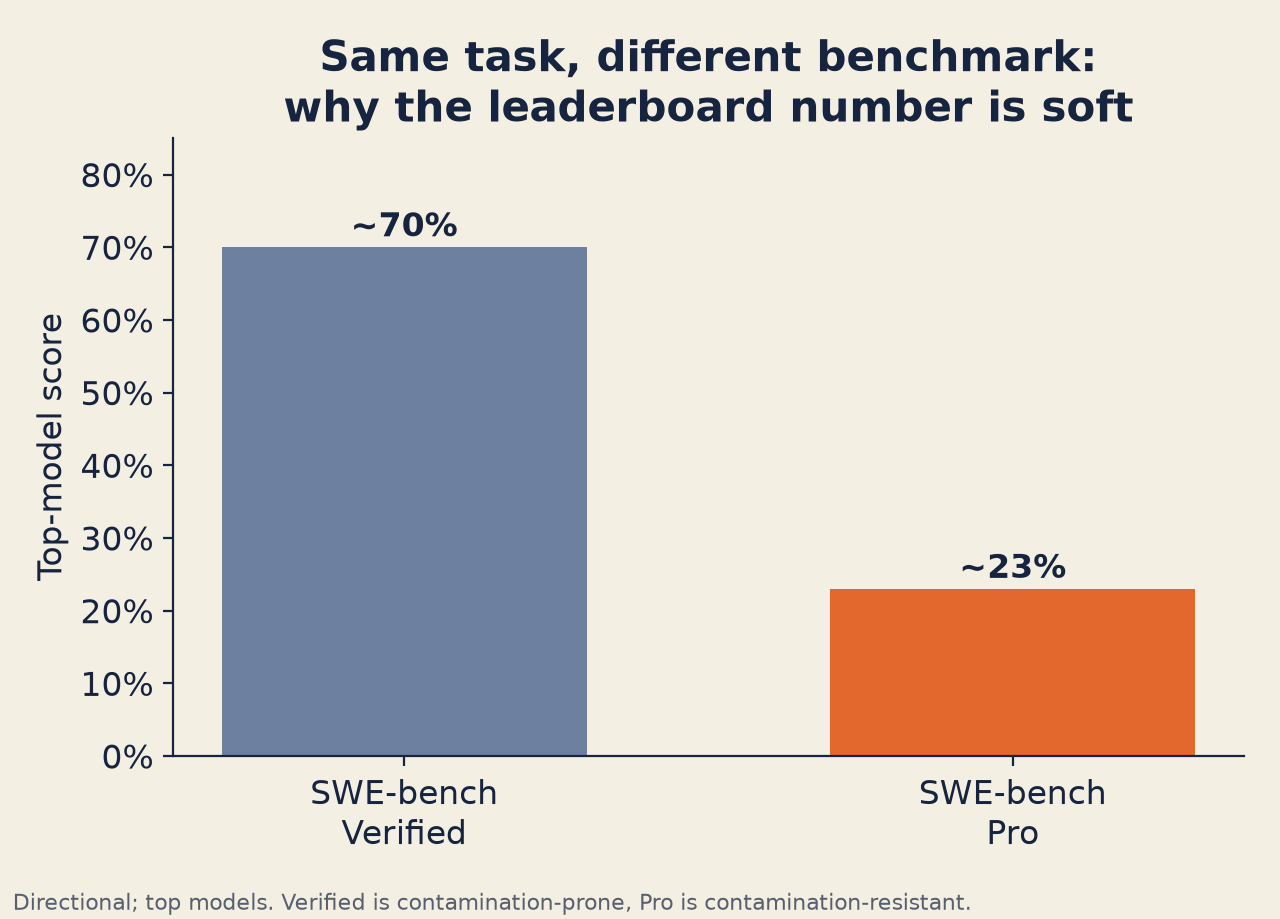
同樣的任務、不同的基準測試:抗污染的測試集說的是完全不同的故事。
這個比喻是:一個學生在去年的考試考了 95%。非常厲害——直到你發現他是把答案卷背了下來。用新教材考他,數字看起來就會非常不同。
對程式碼生成而言,唯一具權威性的訊號,是在你實際的程式碼庫上做評測。在 SWE-bench 上表現好的模型,是在有著常見模式的公開 Python 儲存庫上表現好。你的私有程式碼庫有不同的慣例、不同的抽象、不同的測試結構。表現總是會比基準測試低——問題在於低多少,而答案在不同模型之間差異甚大。
程式碼生成模型選型的實務做法:
- 用 SWE-bench Verified 與 SWE-bench Pro 作為初步篩選的過濾器,淘汰明顯表現差的選項
- 對於生產決策,跑一套私有的評測框架:一組來自你自己程式碼庫、且已知正確解答的代表性任務
- LiveCodeBench 值得納入——它使用模型訓練截止日之後才發布的題目,使污染在結構上難以發生
- 特別要在你最主要的語言與框架上量測。一個為 Python 最佳化的模型,在一個有著複雜匯入關係的 monorepo 裡的 TypeScript 上,可能會有不同的表現。
客戶支援與聊天機器人:TTFT 是你最主要的 UX 指標
對面向客戶的對話應用來說,模型品質的爭論往往次要於一個不會出現在任何基準測試排行榜上的指標:首字延遲(TTFT,Time to First Token)——從送出請求到收到回應第一個字元之間的延遲。
這個比喻是:一家餐廳,服務生立刻就應答你的點餐,對比另一家服務生消失了 30 秒才回來。餐點本身可能一模一樣,但前 30 秒的體驗,塑造了你對整段互動的觀感。使用者把 500 毫秒的 TTFT 感受為「即時」,把 2 秒的 TTFT 感受為「很慢」。在速度可被接受之前,回應的內容幾乎無關緊要。
這對支援應用的模型選型有以下意涵:
- 較小、較快的模型往往帶來更好的使用者體驗,即使它們量測到的輸出品質略低——因為 UX 是由 TTFT 主導的
- 對重複出現的 FAQ 式查詢做語意快取與提示快取,是最主要的成本最佳化——同樣的問題在支援情境中會出現數百次;對穩定上下文做快取能大幅降低每次查詢的成本
- 串流輸出很重要:一個在 300 毫秒內串流出第一個 token 的模型,感覺比另一個在 1.5 秒後才交出完整回應的模型更快,即使兩者的總完成時間相同
對於分類式的支援任務(意圖路由、升級偵測、情緒標記),準確度下限通常用比前沿模型小得多、也便宜得多的模型就能達到。把每一張支援工單都送進 Claude Opus 做意圖分類,就像拿大鐵鎚去掛一個相框。

基準測試陷阱:數字沒告訴你的事
在根據公開基準測試決定採用某個模型之前,有四個值得內化的注意事項:
1. MMLU 已經飽和。 最先進的模型在 MMLU 上的準確度都擠在 2–4% 的範圍內,使它幾乎無法用來區分當前的前沿模型。它是一道下限測試,不是區分器。
2. 同一個模型,在不同框架下分數不同。 兩個團隊用不同的提示格式、少樣本(few-shot)範例與答案擷取邏輯,在同一個任務上跑同一個模型,回報的分數可能相差 10–15%。評測方法本身就是結果的一部分。當你看到一個基準測試數字時,要問:「是誰跑的,用什麼提示設定?」
3. SWE-bench 污染。 SWE-bench Verified(頂尖模型 70% 以上)與 SWE-bench Pro(頂尖模型 23%)之間的落差,說明了污染會多麼劇烈地灌水分數。你讀的是哪一個基準測試,排行榜的排名可能看起來非常不同。
一個公開的 SWE-bench 排行榜。把排名當成方向性參考——同一個模型在不同評測框架下分數可能不同。
4. 你的資料才是唯一具權威性的訊號。 每一個基準測試都是用別人的分布建出來的。你的使用情境有不同的分布——不同的領域詞彙、不同的使用者查詢模式、不同的文件結構。一個在公開基準測試上排第二的模型,在你的特定任務上可能勝過排名第一的模型。要知道答案,唯一的方法就是在你自己的資料上做評測。
Model Advisor 的做法
當我與工程團隊一起做模型選型時,我使用的框架是這樣的:
- 定義你的準確度下限——不是理想中的,而是實際的最低門檻
- 挑選你的評測指標——翻譯用 COMET;RAG 用忠實度(groundedness);程式碼用你自己評測框架上的通過率;支援則用 TTFT + 任務準確度
- 由小到大評測——從最便宜的可行模型開始,往上試,直到跨過你的下限
- 設定重新評測的節奏——模型層級演進得很快;六個月前需要 Sonnet 的任務,現在用 Haiku 可能就能達成
產出的是一個專屬於你使用情境的決策矩陣——不是「用模型 X」,而是「A 類型的任務用模型 X、B 類型的任務用模型 Y,並在信心度低時用升級邏輯轉給模型 Z」。
這正是 DigitalOcean 的 Inference Router 所自動化的:根據任務複雜度,在不同模型層級之間路由請求,而不需要你維護自訂的路由邏輯。決策矩陣變成了設定,而非程式碼。多供應商與多模型路由背後更深層的架構故事,會在本系列的第 5 篇文章中涵蓋。
總結
模型選型不是一次性的決定——它是一個流程。關鍵原則:
- 先建立你的準確度下限,然後找出能跨過它的最便宜模型——而不是反過來做
- 針對你的任務類型使用正確的評測指標:翻譯用 COMET(不是 BLEU)、RAG 用忠實度、程式碼用私有框架上的表現、面向客戶的對話用 TTFT
- 基準測試是篩選用的過濾器,不是最終判決——MMLU 已飽和、SWE-bench 有污染問題,而同一個模型在不同評測框架下分數相差 10–15%
- 你自己的資料才是唯一具權威性的訊號——每一個公開基準測試都是用別人的分布建出來的
- 較小的專才在自己的主場上擊敗較大的通才——低資源翻譯用微調後的 NLLB-200 3.3B、FAQ 分類用一個提示得當的 Haiku
那個貴的模型很少是正確答案。正確答案是能可靠地跨過你準確度下限的最小模型——在你的資料上、你的任務上、用你的指標評測出來的那一個。
參考資料
- What is the best LLM for translation? — Lokalise
- Rapidata Translation Benchmark: DeepL vs DeepSeek-R1/Llama/Mixtral — HuggingFace
- NLLB-200 3.3B Model — Meta / HuggingFace
- SWE-bench Pro Leaderboard — Scale AI
- SWE-bench Verified Leaderboard 2026 — Steel.dev
- AI Translation Companies in 2026: Vendor Comparison — Forasoft

