
利益揭露:我是 DigitalOcean 的 Solutions Architect,所以文中提到 DigitalOcean 產品時,是「業內人的觀點」而非中立第三方——這些地方我都會明確標示,其餘分析則盡量保持廠商中立。以下皆為個人觀點。
一篇關於隱藏推論成本相乘因子的實務論述,搭配 DigitalOcean Serverless Inference 上的實跑量測。跨供應商的模式到處都適用;文中 DigitalOcean 特有的數字來自 inference.do-ai.run 上有記錄的 API 實跑,不是行銷素材。
前言
有位創辦人在一個開發者 Slack 裡貼了張截圖。他們的 Gemini API 帳單在短短一個月內,從 $200 暴增到 $6,000。沒有任何警示被觸發。沒有任何儀表板亮起紅燈。團隊裡也沒有人察覺到任何異樣——直到帳單寄來。

這個故事——記錄於一篇分析 60 多個 LLM 模型的公開報告中——並不是什麼例外。當團隊在不了解完整成本結構的情況下就採用 LLM API,這幾乎就是預設會發生的結果。同一份分析發現,相較於光是透過更好的模型選擇與使用模式就能達到的水準,企業普遍多付了 50–90%。
本文將完整說明這一切究竟為什麼會發生——並提供一套具體的框架,幫你把這道落差補起來。
關於定價的說明: 本文引用的 token 費率是 2026 年 6 月的官方定價,來源為各供應商文件與 DigitalOcean Inference 定價頁。LLM 定價變動非常頻繁——供應商經常調降費率、新增層級、重新命名模型,因此你讀到時看到的數字可能已經不是最新的。請把文中每個數字視為對「模式」的示意,而非即時報價;編列預算前,務必再確認一次當下的實際費率。
重點摘要
- 廣告上標示的輸入 token 價格是地板,不是天花板——真實的生產環境帳單常常是這個數字的 2–3 倍,原因在於五個會層層相乘的因子。
- 輸出 token 的成本是輸入的 3–5 倍,而思考 token 是以輸出費率計費的,卻完全不會出現在使用者看得到的回應裡。
- 非生產環境流量——CI、staging、負載測試、本機開發——會悄悄被算進同一張帳單,而且金額往往不輸給生產環境的花費。
- 長 context 加價可能會讓整個工作階段的每 token 費率翻倍甚至翻到四倍,只要你跨過了供應商的門檻(例如 GPT-5.5 超過 272K 輸入 token)。
- 模型選擇是最大的槓桿:在 DigitalOcean 的實跑中,三個模型跑完全相同的 94 輸入 / 80 輸出分類提示,每請求成本相差達 36 倍,而且純粹是費率造成的。
- 有四個槓桿能補上這道落差——提示快取(prompt caching,快取讀取約打 1 折)、批次處理(約打 5 折)、量大折扣,以及模型路由——但這一切的前提都是對「錢究竟花到哪裡去」具備可見性。
這道落差是結構性的,不是帳務程式出錯
把 LLM 的定價頁面想成一份餐廳菜單。價格看起來很合理,直到你發現那個標出來的價格只是前菜。主菜(輸出 token)要貴上三到五倍。接著還有高級座位的加價(長 context)、看不見的主廚備料服務費(思考 token),而且不知怎地,廚房連你週六早上練習備料的時段都一直在幫你記帳(非生產環境)。
在生產環境中,你的帳單很少會等於 input_tokens × input_rate。供應商拿輸入來報價,是因為那是比較小的數字。生產流量真正付錢的地方是輸出、看不見的思考 token、重複的前綴、非生產環境的重播流量,以及你在毫無察覺中跨過的 context 級距。
團隊照著定價頁面編預算,然後在收到帳單時大吃一驚。一旦你把下面五個相乘因子攤開來看,這個驚嚇其實完全可以預測。這些因子會層層相乘——只修其中一個而忽略其他,落差大部分還是原封不動。
標示價與實際帳單之間落差背後的五個隱藏相乘因子。
隱藏因子 #1:輸出 token 比輸入貴 3–5 倍
每家供應商都拿輸入 token 費率當開場白,因為那是比較小的數字。真正撐起成本的主力是輸出 token——也就是模型生成的那些 token——定價高出 3 到 5 倍。
Claude Sonnet 4.6 的定價是每百萬輸入 token $3.00、每百萬輸出 token $15.00。撰稿當下,DigitalOcean Serverless Inference 也是同樣的拆分。對於一個輸入對輸出比例為 1:2 的典型對話式應用來說,在其他因子都還沒加進來之前,你的有效混合成本就已經是廣告輸入費率的 3 倍了。
這正是那個 50–90% 多付模式背後的主要推手。團隊照著定價頁面上的輸入數字編預算,等到實際帳單反映出更沉重的輸出現實時,才大吃一驚。
該檢查什麼: 拉出過去 30 天你實際的輸入對輸出 token 比例。如果輸出量是輸入的 2 倍或 3 倍,那你的有效費率跟定價頁面上那個數字根本不在同一個量級。
隱藏因子 #2:思考 token 以輸出費率計費,而且完全看不見
具備延伸思考或思維鏈推論能力的模型——Claude 的 adaptive thinking、OpenAI 的 o3 與 o4-mini——會在生成回應的過程中產生「思考 token」。這些是模型內部的推論步驟,永遠不會出現在你的使用者看到的內容裡。
它們是以完整的輸出 token 費率計費的。
把它想成你聘了一位按小時計費的顧問。你只要一頁的備忘錄,他寫只花了 15 分鐘——但他還會把寫下第一個字之前,花在研究、斟酌、打草稿的那 3 個小時也一起跟你收費。備忘錄看起來一模一樣,帳單可不一樣。
在 Claude Opus 4.8(輸出 $25/M token)上,一個有 500 個可見輸出 token 加上 2,000 個思考 token 的回應,成本是同一個回應但不開延伸思考時的 5 倍。你的使用者看到的是 500 個 token 的回應,你付的卻是 2,500 個。
這不是什麼瑕疵——思考 token 能在複雜的推論任務上大幅提升表現。但如果你在開啟延伸思考時沒有限制模型「想多深」,你付的錢可能遠遠超過你的使用情境實際所需的斟酌量。
在當前的前沿模型上,這個控制項的形式已經變了。Claude Opus 4.8 與 Opus 4.7 一定會使用 adaptive thinking——它們已經不再接受固定的 budget_tokens 上限,你改用 effort 參數(low → max)來調整深度。固定的 token 天花板不再是那個旋鈕了,把 effort 對應到任務複雜度才是。
{
"model": "claude-opus-4-8",
"max_tokens": 16000,
"thinking": { "type": "adaptive" },
"output_config": { "effort": "low" },
"messages": [{ "role": "user", "content": "Classify this support ticket." }]
}
json這個請求把一個簡短的分類提示送給 Claude Opus 4.8,開啟 adaptive thinking,但把 effort 設為 low,讓模型在回答之前少花一點看不見的推論 token。Opus 4.8 一定會思考,你關不掉,但你可以讓深度對應到任務。一個工單標籤不需要跟多步驟 agent 工作流一樣的推論預算。把低 effort 搭配簡單提示,就能避免看不見的思考 token 把一張本來應該貼近可見輸出量的帳單灌水。
該檢查什麼: 檢視你的部署有沒有開啟延伸思考,以及深度是否對應到任務。並且每個回應都去看 usage——當 effort 預設偏高時,推論型模型常常在瑣碎任務上就吃掉大半花費。
隱藏因子 #3:非生產環境流量共用同一個 API 帳戶
這裡有個對工程主管特別有感的比喻:想像有家咖啡店,每次有人練習做你點的那杯飲料就跟你收一次錢——不只是把成品端給你的時候才收。咖啡師受訓時拉的每一杯濃縮、測試時重做的每一杯、開店前團隊試喝時做的每一批——通通算到你帳上。
當你的 LLM API 帳戶不去區分生產與非生產用量時,發生的大致就是這種事。
CI 流水線在每一個 pull request 上都會重跑同一批測試情境。開發者在調整提示詞時會在本機反覆跑流程。staging 環境會複製生產流量來做驗證。負載測試則對著模型端點猛打,用來確認應用——而不是模型——能不能擴展。少了環境標籤,這一切全都會照生產環境的規格計費。
Speedscale 對企業 AI 部署的分析記錄了這個模式:大多數團隊都沒注意到自己的 AI 帳單裡有多少來自非生產環境,直到那個數字已經痛到不行。一個用 Claude Sonnet 每天處理 10,000 張工單的中型客服中心,會產生一筆可預測的生產環境花費。再加上 CI 流水線、開發者測試、以及 staging 驗證——真實帳單可能會是你光算生產流量所得數字的 2–3 倍。
該檢查什麼: 依環境(production、staging、CI、local)為你的 API 呼叫加上標籤,讓儀表板能依「來源」把花費分組。第一次做環境拆分時,CI 與 staging 常常就佔了總 token 量的 30–50%。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["MODEL_ACCESS_KEY"],
base_url="https://inference.do-ai.run/v1",
)
response = client.chat.completions.create(
model="anthropic-claude-4.6-sonnet",
messages=[{"role": "user", "content": "Summarize this log line."}],
extra_body={
"metadata": {
"environment": os.environ.get("APP_ENV", "local"),
"service": "ci-test-runner",
}
},
)
print(response.usage)
python這段程式碼透過 OpenAI 相容的 SDK 呼叫 DigitalOcean Serverless Inference,並在每個請求上附加 environment 與 service 的 metadata 標籤。這些標籤是放在 extra_body 裡送出的,讓你可以依來源切分用量記錄——CI runner、staging、生產環境——而不是把每個 token 都當成生產環境的花費。印出 response.usage 則能拿到 token 數,等標籤化的流量分好組之後,用來跟帳單對帳。
隱藏因子 #4:同一個提示,冗長度因模型而異 2–4 倍
Claude 傾向把話說得很完整。o4-mini 則傾向簡潔。同樣一個提示,輸出 token 數可能會因為你用的是哪個模型而相差 2–4 倍。不管哪一種,每一個輸出 token 你都要付錢。
把模型選型想成透過兩條獨立的通道在推動成本會很有幫助:費率(rate)通道(模型每 token 收多少——就是因子 #1)與用量(volume)通道(同一個任務它生成多少輸出 token——就是這一個)。兩者會相乘:把一個話多的模型、以高昂的每 token 費率派去做一份工作,你就在兩個軸上同時多付。稍後我們會用實測把這兩條通道各自隔離出來。
這裡的比喻是電子郵件的長度。請一位注重細節的同事確認一個開會時間,你可能會收到三段話,裡頭塞滿了背景、替代方案和各種但書。請一位簡潔的同事,你得到的是「週二下午 2 點可以」。兩個回答含有同樣的資訊,但其中一個產生起來的成本貴上不少。
到了一定規模,這就很要緊了。如果你用 Claude Sonnet 來做一件你其實只需要一個標籤或是非題決策的任務,而模型每次都回給你一段論述周全的解釋,那你就是在為成千上萬個對你的應用毫無價值的 token 付錢。
短期解法是提示工程,而不是換模型:像是「只回答分類標籤,不要解釋」這種明確的約束,在結構化任務上可以把輸出減少 60–80%。長期來看,正確的做法是把模型的冗長度對應到任務類型——並且要以「端點」為單位測量輸出 token 數,而不是以模型型錄上的條目為單位。
隱藏因子 #5:長 context 加價套用到整個請求
國際數據漫遊的運作方式是這樣的:你的電信業者給你看一個看起來合理的每 MB 費率,一切都好端端的,然後你在沒注意到的情況下跨過了一條國界。突然之間,同樣的動作貴了 4 倍——而且是回溯套用到整個工作階段,不只是門檻之後的那段流量。
LLM 的長 context 定價,運作方式一模一樣。
GPT-5.5(依 OpenAI 的模型文件)在 272K 輸入 token 以下的定價是輸入 $5/M、輸出 $30/M。超過 272K 輸入 token 之後,定價會切換成輸入 $10/M、輸出 $45/M——而且是套用到整個工作階段,不只是門檻之上的那些 token。
Gemini 3.1 Pro Preview(依 Google 的定價文件)在 200K context 以內收取輸入 $2.00/M、輸出 $12.00/M。超過 200K,費率就跳到輸入 $4.00/M、輸出 $18.00/M——而且關鍵在於,那個請求裡的所有 token(輸入和輸出)都會以長 context 費率計費,不只是超過門檻的那些 token。
| 模型 | 標準費率(每 M 輸入 / 輸出) | 門檻 | 長 context 行為 |
|---|---|---|---|
| GPT-5.5 | $5 / $30 | >272K 輸入 token | 2 倍輸入 / 1.5 倍輸出,整個工作階段 |
| Gemini 3.1 Pro Preview | $2 / $12 | >200K 輸入 token | $4 / $18 每 M,整個請求 |
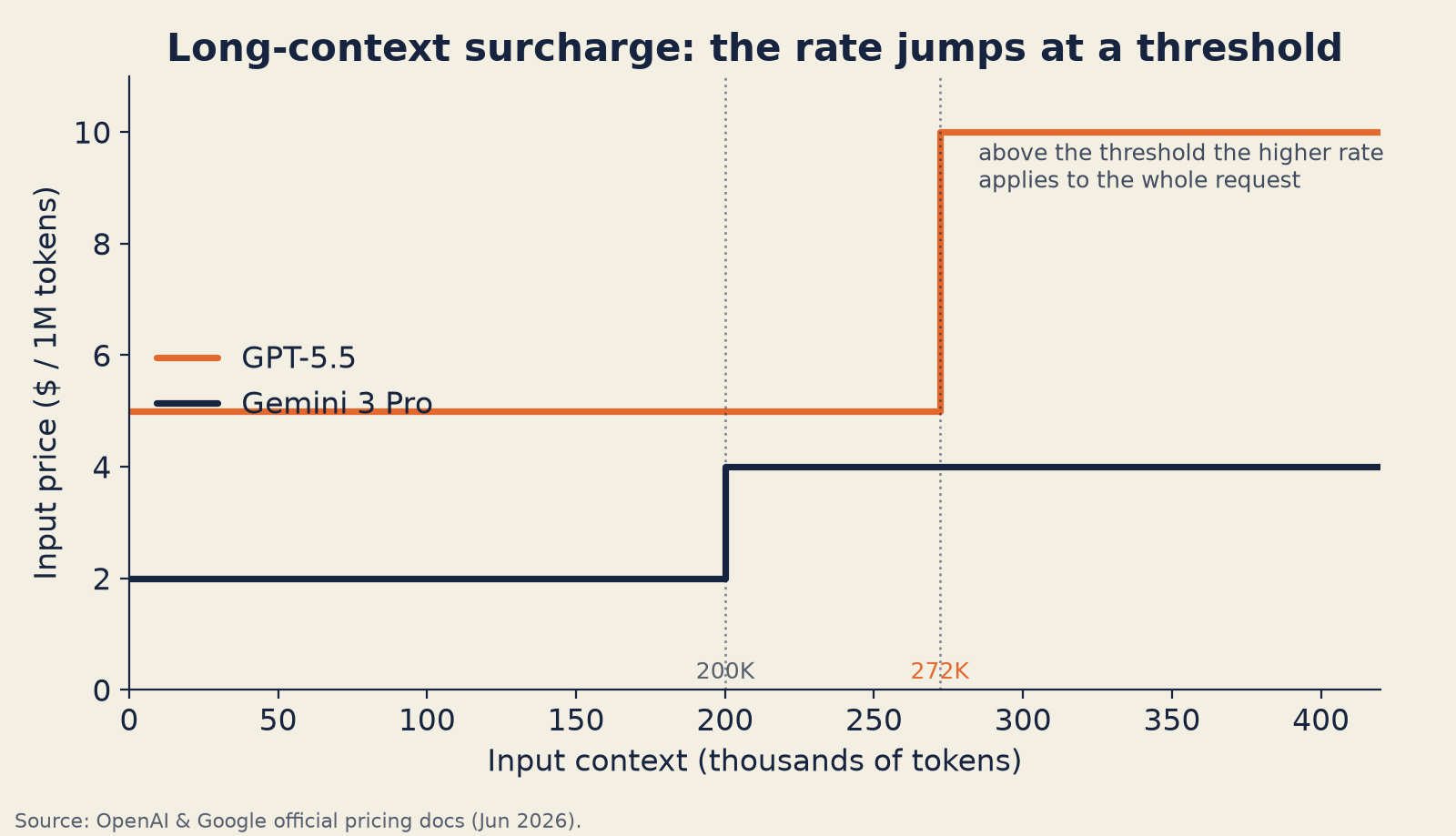
一旦跨過供應商的 context 門檻,較高的費率會套用到整個請求——不只是超過門檻的那些 token。
把大塊文件硬塞進 context 的 RAG 流水線,以及在很長的對話歷史中跑推論的多輪 agent,都會在相當可觀比例的請求上跨過這些門檻。如果你還沒拿自己的 context 長度去對照供應商的加價門檻,那你很可能在大量流量上付了雙倍卻渾然不知。
該檢查什麼: 拿你的 p95 與 p99 輸入 context 長度去對照每一家供應商的級距邊界。如果這些數字正逼近任何一個門檻,就要搞清楚究竟有多少比例的請求正以長 context 費率計費。
我們在 DigitalOcean Serverless Inference 上實測到什麼
上面那些相乘因子與供應商無關。本節的數字來自在 https://inference.do-ai.run/v1 上的實跑 API,記錄於 DigitalOcean 的 Multi-Model API Cost Governance with the Inference Router 教學(資料截至 2026 年 6 月 16 日)。方法:固定提示、temperature=0、token 數讀自回應的 usage,成本則以實跑當下公開的 DigitalOcean Inference 費率計算。(這裡一樣適用揭露原則——我任職於 DigitalOcean——但這些是有記錄的 API 實測,不是行銷宣稱,而且背後的模式在任何供應商上都會重現。)
模型選型稅:token 完全相同,成本卻差 36 倍。 模型選擇透過兩條獨立通道推動成本:模型收取的每 token 費率,以及它產生的輸出量(冗長度,因子 #4)。第一項實測要隔離的是費率通道。同一個分類提示、三個模型、完全相同的 token 形狀(94 輸入 / 80 輸出)——輸出比例與冗長度都被固定住,唯一的變數是價格:
| 模型 | 每請求成本(2026 年 6 月 16 日實跑) | 對比最便宜路徑 |
|---|---|---|
openai-gpt-oss-20b | $0.00004070 | 基準 |
openai-gpt-5 | $0.00091750 | 22.5× |
anthropic-claude-4.6-sonnet | $0.00148200 | 36× |
openai-gpt-oss-20b 的計算方式:(94 × $0.05 + 80 × $0.45) / 1,000,000 = $0.00004070。
當 openai-gpt-oss-20b 就能跨過準確度門檻時,卻把每一筆分類都送給 Sonnet,就是一筆 36× 的每請求稅——純粹付在費率上,冗長度都還沒加進來。以每月 70 萬筆分類請求算,這道差距是 $28.49 對 $1,037.40,而且只是路由這一項。量大折扣救不了模型錯配。
這與 DigitalOcean 在 Metrics that Matter with Serverless Inference 中更大範圍的基準測試一致:在同一家供應商上,每個完成答案的成本在整個模型型錄之間相差約 230 倍。供應商的標示價格讓成本差幾個百分點,模型選擇讓它差好幾個數量級。
推論任務的輸出量:約為分類成本的 840 倍。 同一個供應商、不同任務,6 月 16 日的實跑:
| 路徑 | 模型 | Token(輸入 / 輸出) | 每請求成本 |
|---|---|---|---|
| 分類 | openai-gpt-oss-20b | 94 / 80 | $0.00004070 |
| 客戶問答 | anthropic-claude-4.6-sonnet | 412 / 292 | $0.00445200 |
| 推論 | openai-gpt-5 | 891 / 3,411 | $0.03417625 |
推論路徑的每請求成本比分類貴上約 840 倍($0.03417625 對 $0.00004070)。GPT-5 的輸入費率($1.25/M)比 Sonnet($3.00/M)還低,所以這不是費率通道造成的效應——帳單爆掉是因為推論生成了 3,411 個輸出 token,而分類只有 80 個。這就是因子 #2、以及因子 #1 用量通道的數字化版本:輸出量(包含在可見答案之前就計費的思考 token)主宰了成本。
重現這項量測。 拿你自己的 Model Access Key 跑一次。它會印出成本歸因所需的 usage 區塊:
curl -s -X POST "https://inference.do-ai.run/v1/chat/completions" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openai-gpt-oss-20b",
"temperature": 0,
"messages": [
{"role": "system", "content": "Classify the ticket. Reply with one word: billing, bug, how-to, or account."},
{"role": "user", "content": "I was charged twice for my subscription last month."}
]
}' | python3 -c "import sys,json; u=json.load(sys.stdin)['usage']; print(u)"
bash這一行指令用 temperature=0 把一個固定的分類提示送給 openai-gpt-oss-20b,並印出回應的 usage 區塊,讓你看到自己實際被計費的 prompt_tokens 與 completion_tokens。換成 anthropic-claude-4.6-sonnet 用完全相同的提示再跑一次,usage 的差距就是你帳單今天正在扛的那筆模型選型稅:任務形狀相同,只是每 token 費率不同。
完整的 router 設定、任務策略,以及 x-model-router-selected-route 回應標頭,都記錄在 Inference Router 操作指南裡。
可見性要排在最佳化之前
貫穿這五個隱藏相乘因子的共同點,就是它們在預設情況下都是看不見的。大多數 LLM API 的計費儀表板只會顯示總 token 數和總花費。它們不會拆解出:
- 依環境區分的 token(生產對非生產)
- 快取命中率與錯失的省下
- 思考 token 對可見輸出 token 的比例
- 各請求的長 context 加價暴露程度
- 各任務類型的輸出 token 分佈
少了這份拆解,你就是在盲目最佳化。建立這種可見性是一次性的投資,卻會持續回本。本文裡的每一項最佳化都從「該檢查什麼」開始——而少了在你推論層上的儀表化可觀測性,這些檢查一項都做不了。
一個粗略的起點:直接用 DigitalOcean/Anthropic 的公開費率,從 API 已經回傳的 usage 計數估算混合成本。把它接到你的推論 log 上:
#!/usr/bin/env python3
"""Estimate blended LLM cost from token usage counters."""
from dataclasses import dataclass
@dataclass
class ModelRates:
input_per_m: float
output_per_m: float
cache_read_per_m: float = 0.0
RATES = {
"anthropic-claude-4.6-sonnet": ModelRates(3.00, 15.00, 0.30),
"openai-gpt-oss-20b": ModelRates(0.05, 0.45),
}
def estimate_cost(model, input_tokens, output_tokens, cache_read_tokens=0, thinking_tokens=0):
rates = RATES[model]
billable_output = output_tokens + thinking_tokens
input_cost = (input_tokens / 1_000_000) * rates.input_per_m
cache_cost = (cache_read_tokens / 1_000_000) * rates.cache_read_per_m
output_cost = (billable_output / 1_000_000) * rates.output_per_m
total = input_cost + cache_cost + output_cost
headline = (input_tokens / 1_000_000) * rates.input_per_m
return {
"total_usd": round(total, 4),
"input_only_usd": round(headline, 4),
"multiplier_vs_input_rate": round(total / headline, 2) if headline else 0.0,
}
# 1M input, 2M output, 500K thinking: multiplier ~13.5× vs input-only estimate
print(estimate_cost("anthropic-claude-4.6-sonnet", 1_000_000, 2_000_000, thinking_tokens=500_000))
python這個小工具會把原始的 token 計數轉成一個包含輸出與思考 token(而不只是輸入)的金額估計。multiplier_vs_input_rate 這個欄位會把「定價頁面上的算法」與「你實際付的錢」之間的落差攤開來:最下面那個例子——1M 輸入、2M 輸出、500K 思考——相對於只算輸入的估計,倍數大約是 13.5 倍。用它來標記出混合成本偏離你預算的那些端點。
依槓桿效益排序的四個手段
假設你會繼續留在託管 API 上,以下就是在最佳化投入上回報最高的四個槓桿。
1. 提示快取——降低重複前綴的成本
提示快取(prompt caching)會在多個請求之間重複使用已經算好的前綴——你的系統提示、few-shot 範例,以及 RAG context 範本——省去每次呼叫都重新處理同一批 token 的成本。
把它想成影印機的暖機:第一張要等一下,但第二張到第兩千張既即時又便宜。Anthropic 的快取讀取以基礎輸入費率的 10% 計費(定價文件)——也就是打 1 折。快取寫入則是 1.25 倍(5 分鐘 TTL)或 2 倍(1 小時 TTL),你付一次錢把前綴存起來,之後每次命中都在省。一個 1M token 的系統提示搭配 80% 的快取命中率,會實質改變輸入端的成本結構。
要如何做到——包括那個會把命中率打到個位數的常見「單一欄位」錯誤——都在本系列第 3 篇,以及 DigitalOcean 的 Advanced Prompt Caching 裡有完整說明。
2. 批次 / 非同步處理——約打 5 折,不需要工程投入
對於任何不需要同步回應的工作負載——文件處理、夜間分析、大量分類、評測跑批——批次推論提供大約 5 折的折扣,搭配 24 小時的 SLA。如果你的工作能容忍延遲,卻還在呼叫同步端點,那你等於把最容易拿到的折扣留在桌上。
3. 量大折扣——記得去問
當每月花費夠高時,議定折扣就會啟動。許多符合資格的團隊只是單純沒去問。這個對話值得開啟。
4. 模型路由——流量混合多種任務類型時最大的槓桿
最大的單一槓桿,就是把簡單的請求導向更小、更便宜的模型。Claude Haiku 4.5 的輸入是 $1.00/M;Claude Sonnet 4.6 的輸入是 $3.00/M——價差 3 倍;而如果有一個夠強的開源權重模型能跨過你的準確度下限,差距會拉大到 10 倍以上。這正是前面實測那筆 36× 每請求稅、從「修正端」看過去的樣子:對於更小的模型就能產出同等品質的任務(分類、摘要、從檢索到的 context 中回答 FAQ),跑 Sonnet 就是浪費。
挑戰在於如何把這套路由落實到日常運作中,又不必維護自製的路由邏輯。Inference Router 會在 inference.do-ai.run 上自動處理「任務對模型」的派送,不需要在應用端寫路由邏輯。在 DigitalOcean 的成本治理實跑中,把一個 70 萬 / 25 萬 / 5 萬(分類 / 問答 / 推論)的流量組合透過 router 路由,用上面同一批每請求數字,月成本比 Sonnet-only 基準降低 39.6%、比 Opus-only 降低 63.7%。如何不自己造輪子就做到這件事的架構,會在本系列第 5 篇裡說明。
為什麼按 token 計費與路由會對應到這些相乘因子
本文刻意保持供應商中立,因為這些模式適用於每一家 LLM API 供應商。話雖如此:這些問題有一部分是架構性的,而計費與路由的機制正好一項一項對應到前面的相乘因子。
因子 #3(非生產環境洩漏)是一個可觀測性問題。共用一把 API 金鑰、按 token 計費,預設並不會把環境區分開來。修法是在請求的 metadata 裡加標籤,再做一個依 environment 把 usage 分組的儀表板。DigitalOcean Serverless Inference 是用 API 回傳的同一個 usage 區塊來計費的,所以你的 log 管線與你的帳單共用同一個事實來源。
模型選擇同時驅動因子 #4(冗長度)與費率落差,而兩者都是架構問題。當你用同一個前沿模型去服務分類和推論,你就會在兩條通道上同時用前沿價格買下單字標籤:較高的每 token 費率(實測到的 36× 分類溢價),以及話多的模型在同一任務上更高的輸出量。
Inference Router 會把每個請求導向最適合該任務的模型。想了解運作原理,參見 Inference Router 架構深入解析。
依任務複雜度來路由,能讓平均成本與任務價值成比例。分類流量留在 openai-gpt-oss-20b。問答留在 Sonnet,並用 session pinning 維持 KV cache 的熱度。推論則只在輸出量足以正當化費率時才升級到 GPT-5。這套架構直接對付因子 #1、#2 與 #4,但它取代不了因子 #3 所需的環境標籤。
至於部署模式的取捨——什麼時候按 token 計費的 serverless 該讓位給按 GPU 小時計費的 dedicated——可以參考 Serverless vs Dedicated vs Batch Inference 與 Dedicated vs Serverless Inference as You Scale。
但不管你在哪個平台上,前提都一樣:搞清楚你真實的成本結構。對 token 類型拆解、環境標籤、快取命中率與 context 長度分佈具備可見性的團隊,總是能找到可觀的省下空間——靠的不是什麼花招,而是終於看見了錢都花到哪裡去。
總結:五個隱藏相乘因子
網站上的價格與你實際付出的金額之間的落差,來自五個會層層相乘的因素:
- 輸出 token 比輸入 token 貴 3–5 倍——而大多數生產工作負載都是輸出偏重的
- 思考 token 以完整的輸出費率計費,且在回應中看不見
- 非生產環境——CI、staging、本機測試——會算進同一張帳單,而且金額常常超出預期
- 輸出冗長度 因模型而異 2–4 倍——放任的冗長度是有成本卻無品質
- 長 context 加價 會在大多數團隊從沒拿自己的 p95 context 長度去對照過的門檻上,讓每 token 費率翻倍甚至翻四倍
補上這道落差的四個槓桿:提示快取、為非同步工作負載做批次處理、量大折扣,以及模型路由。在 2026 年 6 月的 DigitalOcean 實跑中,光是路由這一項,就讓一個貼近現實的流量組合比 Sonnet-only 基準低了 39.6%。
而這一切的前提是可見性。少了依環境的標籤、快取命中率監控,以及各任務類型的 token 拆解,你就是在盲飛——而盲飛正是一筆 $200 的帳單變成 $6,000 驚喜的方式。
這是「生產環境中的推論」五篇系列文章的第 1 篇。第 2 篇談模型選擇方法論。第 3 篇談提示快取實戰。第 4 篇檢視全端 AI 應用的總持有成本。第 5 篇談多供應商路由架構。
參考資料
- Multi-Model API Cost Governance with the Inference Router — DigitalOcean(2026 年 6 月實跑)
- Metrics that Matter with Serverless Inference — DigitalOcean(每答案成本基準)
- Why Serverless Inference Consistency Varies on the Same Model — DigitalOcean(TTFT 測試)
- Anthropic API Pricing — Anthropic
- DigitalOcean Inference Pricing — DigitalOcean
- GPT-5.5 Model Documentation — OpenAI
- Gemini API Pricing — Google
- I Analyzed 60+ LLM Models and Found Companies Overpay by 50-90% — DEV Community
- The Hidden AI Bill: Why Non-Prod LLM Costs Spiral — Speedscale
- Inference Router:架構深入解析 — DigitalOcean

