
Disclosure: I'm a Solutions Architect at DigitalOcean, so when I mention DigitalOcean products it's an informed-insider view, not a neutral one — I flag those moments clearly and keep the analysis vendor-neutral wherever the topic allows. The opinions here are my own.
Introduction
A common pattern among engineering teams new to production LLM work: they pick a model from the top of a leaderboard, integrate it, and then spend the next several months trying to reduce the bill. The sequence is backwards.
Model selection — not infrastructure, not prompt optimization, not batching strategy — is the single biggest lever on both quality and cost in a GenAI deployment. The difference between Claude Sonnet 4.6 and Claude Haiku 4.5 on a simple classification task is roughly 12× in price. If Haiku produces equivalent quality for your specific task, every day you spend on Sonnet is 12× overpayment.
The challenge is that most teams pick models the wrong way: they look at benchmark leaderboards, identify the highest scorer, and ship it. This article explains why that produces suboptimal results — and what the right evaluation process actually looks like, illustrated through four distinct use case categories.
Key Takeaways
- Model selection — not hardware — is the single biggest lever on both GenAI cost and quality.
- Establish your accuracy floor first, then pick the smallest model that clears it — not the top of the leaderboard.
- Use the right metric per task: COMET (not BLEU) for translation, faithfulness/groundedness for RAG, a private harness for code, TTFT for customer-facing chat.
- Benchmarks are screening filters, not verdicts: MMLU is saturated, SWE-bench Verified is contamination-prone (~70% vs ~23% on the harder Pro set), and the same model can score 10–15% differently across evaluation harnesses.
- Your own data is the only authoritative signal — and smaller specialists routinely beat larger generalists on their home turf.
The Selection Framework: Accuracy Floor First, Then Cost
The correct mental model for model selection is not "find the best model" — it's "find the accuracy floor for your task, then find the smallest model that clears it."
Think of it like hiring a contractor. You don't hire a structural engineer to repaint a room — you hire the person with the skills appropriate to the job. If your task requires nuanced tone in marketing copy, you probably need the senior engineer. If it requires extracting a date from a document, the junior hire who's 80% cheaper will do fine. The mistake isn't always hiring the wrong person — it's hiring the expensive one without checking whether the cheaper one would do.
Pour the candidates through your accuracy floor; keep the smallest model that clears it.
The process works like this:
- Define your accuracy floor — what's the minimum acceptable performance on the specific metrics that matter for your use case? Not "as good as possible," but the actual threshold below which the product breaks.
- Run evaluation on your own data — use representative samples from your production distribution, not the benchmark's distribution.
- Find the smallest model that clears your floor — start small and work up. Models that pass your eval are candidates; the cheapest candidate wins.
- Revisit when models update — provider model releases happen frequently. The cheapest model that cleared your floor six months ago might have been leapfrogged by a new tier.
Every point in this article applies that same logic to four specific use case categories.
Translation: A Case Study in Metric Mismatch
Translation is a useful case study because it exposes a fundamental flaw in how many teams evaluate LLMs: the metrics that are easy to compute often don't measure what actually matters.
BLEU vs. COMET: Why the Standard Metric Lies
BLEU — the traditional machine translation metric — counts n-gram overlaps between the model's output and a reference translation. It's fast, deterministic, and easy to compute. It's also a poor predictor of quality for anything that requires nuance.
Think of BLEU as evaluating a poem by counting how many rhymes it has. A poem that rhymes perfectly but says nothing interesting scores well. A poem that captures an emotion you've never seen expressed before but breaks the rhyme scheme scores poorly. The metric optimizes for the wrong thing.
COMET (Crosslingual Optimized Metric for Evaluation of Translation) is a neural metric trained on human judgments. It correlates much better with how actual human readers evaluate translation quality — and critically, it can invert BLEU rankings. A model that scores higher on BLEU sometimes scores lower on COMET, because human quality isn't about n-gram overlap.
For any serious translation evaluation, COMET should be your primary metric, with BLEU kept only as a sanity check.
DeepL vs. LLMs: Speed Is the Deciding Variable for Bulk Work
For high-volume translation, the speed gap between DeepL and LLMs is decisive. Google's Neural Machine Translation engine delivers results in milliseconds — up to 20× faster than LLMs. DeepL performs comparably at high throughput. For bulk document translation pipelines where you're processing thousands of segments per hour, that speed difference translates directly to infrastructure cost.
Bulk translation: NMT is the fast stamping press; an LLM is the careful scribe — slower, but better with nuance.
LLMs have a different profile: they win on long-form context, idioms, low-resource languages, and brand-sensitive copy where tone matters. Lokalise's blind study comparing five engines across English→German, Polish, and Russian — evaluated by native speakers using pairwise comparison — found Claude 3.5 achieving the highest "good" rating at 78%, outperforming both GPT-4o and all three NMT engines tested.
Rapidata went further: they ran a comparison of DeepL versus DeepSeek-R1, Llama, and Mixtral using feedback from over 51,000 native speakers, with the dataset now publicly available on Hugging Face. The conclusion was nuanced — neither category dominates across all language pairs and content types.
The 2026 consensus in the localization industry:
| Use Case | Recommended Approach |
|---|---|
| High-volume, repetitive documents (contracts, product descriptions) | DeepL or Google NMT as primary engine |
| Marketing copy, brand voice, tone-sensitive content | LLM (Claude) for final adaptation |
| Low-resource language pairs | Fine-tuned NLLB-200 3.3B often outperforms generic 7-8B LLMs |
| Domain-specific terminology (legal, medical) | Fine-tuned model on domain corpus |
| Real-time user-facing translation at scale | NMT; LLMs too slow for synchronous UX |
The critical insight: for low-resource languages and domain-specific pairs, fine-tuned NLLB-200 3.3B — a 3.3 billion parameter model — still outperforms generic 7-8B LLMs. A smaller specialist beats a larger generalist on their home turf.
The main blocker in AI localization is not technology — it's trust. Post-editing workflows exist precisely because production teams aren't yet ready to publish LLM output without a human checkpoint, regardless of benchmark scores. The evaluation methodology has to account for this: it's not just "does this output score well?" but "would a native speaker trust this without review?"
RAG Pipelines: Evaluate the Full Chain, Not the Model in Isolation
RAG (Retrieval-Augmented Generation) evaluation is where teams most often make the mistake of evaluating only the generation step. The full pipeline has three places where quality can degrade:
- Embedding quality — does the retrieval system surface the right chunks?
- Retrieval precision — are the top-k results actually relevant?
- Generation faithfulness — does the model stick to the retrieved context, or does it hallucinate?
The third metric — faithfulness, also called groundedness — is the dominant quality signal for RAG. A model that summarizes retrieved context accurately is valuable. A model that confidently generates plausible-but-wrong answers that aren't in the retrieved context is dangerous, regardless of how good its benchmark scores are.
Think of evaluating a RAG pipeline like evaluating a research assistant. You don't just test whether they can write clearly — you test whether they only cite what's actually in the documents you gave them, and don't confabulate sources that support their answer.
Practical RAG model selection:
- Run evaluation separately on retrieval quality (does the right content come back?) and generation quality (is the answer faithful to what came back?)
- Measure hallucination rate on held-out examples where you know the ground truth
- Prompt caching of stable context (system prompt + RAG template) is the dominant cost lever — a well-cached RAG pipeline sees 70-80% of input tokens served from cache at 10% of the base input price. Choose the model and prompt structure simultaneously; you can't retrofit caching onto a poorly structured prompt.
For most RAG use cases, mid-tier models (Claude Sonnet, GPT-4o mini) outperform the expected quality gap vs. frontier models because faithfulness is a controllable behavior with good prompting — it doesn't require maximum model intelligence. Spend the evaluation time measuring faithfulness, not benchmarking raw intelligence.
Code Generation: Why Private Codebases Always Underperform Benchmarks
The canonical benchmark for code generation agents is SWE-bench — specifically SWE-bench Verified (500 human-validated Python tasks) for initial screening, and increasingly SWE-bench Pro for harder signal.
Here's the important context:
SWE-bench Verified has contamination problems. OpenAI deprecated reporting against it in February 2026 after audits found that many benchmark tasks had solutions leakable from issue text, and that models recalled file paths from training data up to 76% of the time. Top models score 70%+ on Verified. On SWE-bench Pro — a contamination-resistant alternative built by Scale AI — top models score around 23%. That gap tells you something important about what the leaderboard is actually measuring.
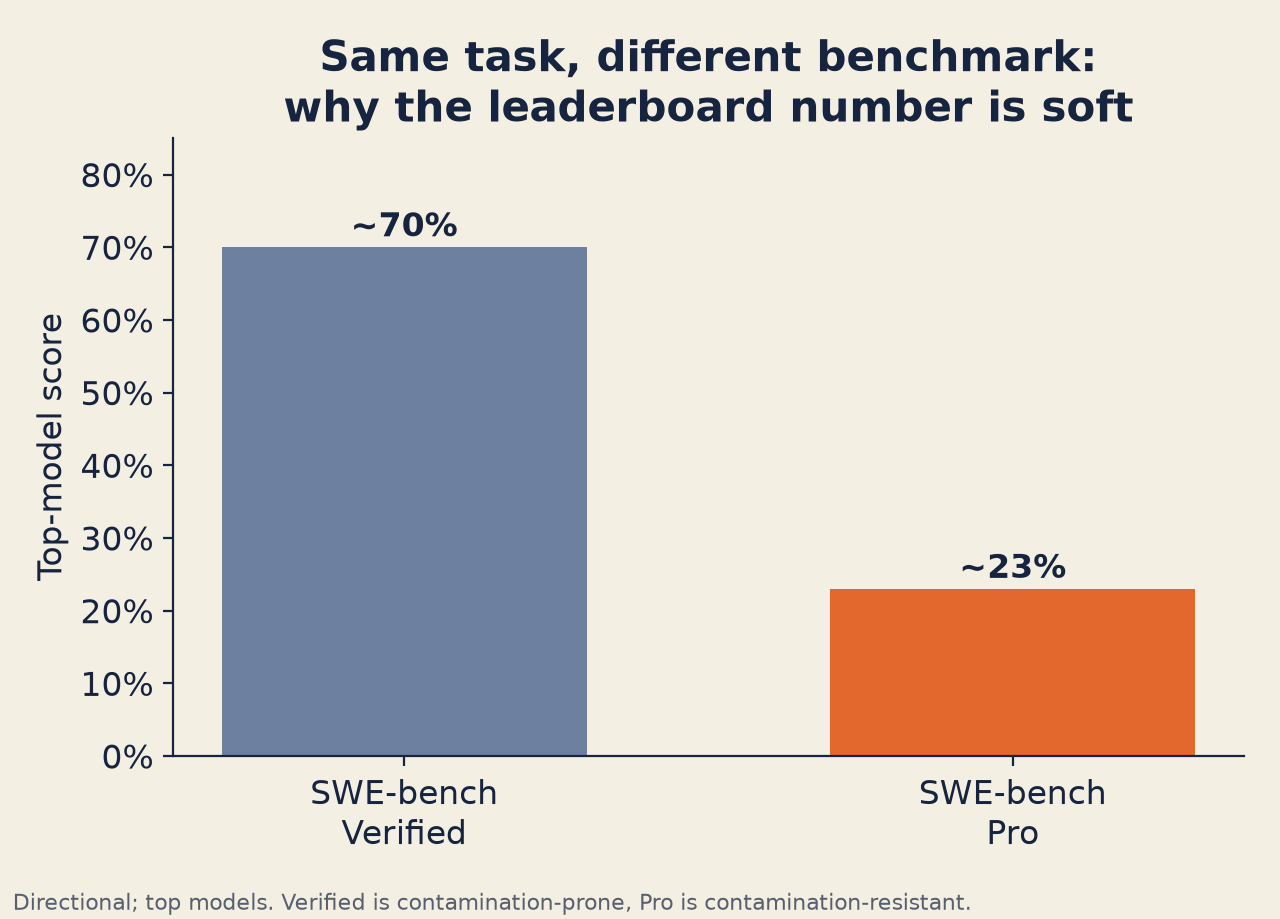
Same task, different benchmark: the contamination-resistant set tells a very different story.
The analogy: a student who scored 95% on last year's exam. Very impressive — until you learn they memorized the answer key. Test them on new material and the number looks very different.
For code generation, the only authoritative signal is evaluation on your actual codebase. Models that perform well on SWE-bench do so on public Python repositories with common patterns. Your private codebase has different conventions, different abstractions, different test structures. Performance is always lower than the benchmark — the question is how much lower, and the answer varies substantially across models.
Practical code generation model selection:
- Use SWE-bench Verified and SWE-bench Pro as initial screening filters to eliminate obviously poor performers
- For production decisions, run a private evaluation harness: a set of representative tasks from your own codebase with known correct solutions
- LiveCodeBench is worth including — it uses problems released after model training cutoffs, making contamination structurally difficult
- Measure on your top languages and frameworks specifically. A model optimized for Python might behave differently on TypeScript in a monorepo with complex imports.
Customer Support and Chatbots: TTFT Is Your Primary UX Metric
For customer-facing chat applications, the model quality debate is often secondary to a metric that doesn't appear on any benchmark leaderboard: Time to First Token (TTFT) — the delay between sending a request and receiving the first character of the response.
The analogy: a restaurant where the waiter immediately acknowledges your order versus one where they disappear for 30 seconds before returning. The meal itself might be identical, but the experience of the first 30 seconds shapes your perception of the entire interaction. Users perceive a 500ms TTFT as "instant." They perceive a 2-second TTFT as "slow." The content of the response barely registers until the speed is acceptable.
Implications for model selection in support applications:
- Smaller, faster models often deliver better user experience even if their measured output quality is marginally lower — because the UX is dominated by TTFT
- Semantic and prompt caching of repeated FAQ-style queries is the dominant cost optimization — the same questions appear hundreds of times in support contexts; caching stable context dramatically reduces per-query cost
- Streaming output matters: a model that streams the first token in 300ms feels faster than one that delivers a complete response after 1.5 seconds, even if the total completion time is the same
For classification-style support tasks (intent routing, escalation detection, sentiment tagging), the accuracy floor is typically reachable by models much smaller and cheaper than frontier models. Routing every support ticket through Claude Opus for intent classification is like using a sledgehammer to hang a picture frame.

The Benchmark Trap: What the Numbers Don't Tell You
Before committing to a model based on public benchmarks, there are four caveats worth internalizing:
1. MMLU is saturated. State-of-the-art models cluster within 2–4% accuracy on MMLU, making it nearly useless for distinguishing between current frontier models. It's a floor test, not a differentiator.
2. Same model, different scores across harnesses. Two teams running the same model on the same task with different prompting formats, few-shot examples, and answer-extraction logic can report scores that differ by 10–15%. The evaluation methodology is part of the result. When you see a benchmark number, ask: "run by whom, with what prompting setup?"
3. SWE-bench contamination. The gap between SWE-bench Verified (70%+ for top models) and SWE-bench Pro (23% for top models) illustrates how dramatically contamination inflates scores. Leaderboard rankings can look very different depending on which benchmark you're reading.
A public SWE-bench leaderboard. Treat the ranking as directional — the same model can score differently depending on the evaluation harness.
4. Your data is the only authoritative signal. Every benchmark was built from someone else's distribution. Your use case has a different distribution — different domain vocabulary, different user query patterns, different document structures. A model that ranks second on a public benchmark may outperform the top-ranked model on your specific task. The only way to know is to evaluate on your own data.
The Model Advisor Approach
When working with engineering teams on model selection, the framework I use looks like this:
- Define your accuracy floor — not aspirational, the actual minimum threshold
- Pick your evaluation metric — for translation, COMET; for RAG, faithfulness/groundedness; for code, pass rate on your own harness; for support, TTFT + task accuracy
- Evaluate smallest-to-largest — start with the cheapest viable model, work up until you clear your floor
- Set a re-evaluation cadence — model tiers evolve quickly; what required Sonnet six months ago may now be achievable with Haiku
The output is a decision matrix specific to your use case — not "use model X" but "use model X for tasks of type A, model Y for tasks of type B, with escalation logic to model Z when confidence is low."
This is exactly what DigitalOcean's Inference Router automates: routing requests across model tiers based on task complexity, without requiring you to maintain custom routing logic. The decision matrix becomes configuration, not code. The deeper architectural story behind multi-provider and multi-model routing is covered in Article 5 of this series.
Summary
Model selection is not a one-time decision — it's a process. The key principles:
- Establish your accuracy floor first, then find the cheapest model that clears it — not the other way around
- Use the right evaluation metric for your task type: COMET for translation (not BLEU), faithfulness for RAG, private harness performance for code, TTFT for customer-facing chat
- Benchmarks are screening filters, not verdicts — MMLU is saturated, SWE-bench has contamination issues, and the same model scores 10–15% differently across evaluation harnesses
- Your own data is the only authoritative signal — every public benchmark was built from someone else's distribution
- Smaller specialists beat larger generalists on their home turf — fine-tuned NLLB-200 3.3B for low-resource translation, a well-prompted Haiku for FAQ classification
The expensive model is rarely the right answer. The right answer is the smallest model that reliably clears your accuracy floor — evaluated on your data, on your task, with your metric.
References
- What is the best LLM for translation? — Lokalise
- Rapidata Translation Benchmark: DeepL vs DeepSeek-R1/Llama/Mixtral — HuggingFace
- NLLB-200 3.3B Model — Meta / HuggingFace
- SWE-bench Pro Leaderboard — Scale AI
- SWE-bench Verified Leaderboard 2026 — Steel.dev
- AI Translation Companies in 2026: Vendor Comparison — Forasoft

