
Disclosure: I'm a Solutions Architect at DigitalOcean, so when I mention DigitalOcean products it's an informed-insider view, not a neutral one — I flag those moments clearly and keep the analysis vendor-neutral wherever the topic allows. The opinions here are my own.
A practitioner argument about hidden inference cost multipliers, with live-run measurements from DigitalOcean Serverless Inference. The cross-provider patterns apply everywhere; the DigitalOcean-specific numbers come from documented API runs on inference.do-ai.run, not from marketing claims.
Introduction
A founder posted a screenshot in a developer Slack. Their Gemini API bill had gone from $200 to $6,000 in a single month. No alerts had fired. No dashboard had turned red. No one on the team noticed anything unusual — until the invoice arrived.

This story, documented in a public analysis of 60+ LLM models, is not exceptional. It is the default outcome when teams adopt LLM APIs without understanding the full cost anatomy. The same analysis found that companies routinely overpay by 50–90% compared to what's achievable with better model selection and usage patterns alone.
This article walks through exactly why that happens — and gives you a concrete framework for closing the gap.
A note on pricing: Token rates cited here reflect June 2026 list prices from provider docs and DigitalOcean Inference pricing. LLM pricing is highly dynamic — providers cut rates, add tiers, and rename models constantly, so the figure you see may not be current by the time you read this. Treat every number here as illustrative of the pattern, not a live quote, and confirm live rates before you budget.
Key Takeaways
- The advertised input-token price is a floor, not a ceiling — real production bills routinely run 2–3× higher because of five compounding multipliers.
- Output tokens cost 3–5× more than input, and reasoning/"thinking" tokens are billed at output rates while never appearing in the user-facing response.
- Non-production traffic — CI, staging, load tests, local development — silently rolls into the same bill and often rivals production spend.
- Long-context surcharges can double or quadruple per-token rates for the entire session once you cross a provider's threshold (e.g. GPT-5.5 above 272K input tokens).
- Model choice is the largest lever: in live DigitalOcean runs, three models on an identical 94-in / 80-out classify prompt spanned a 36× per-request cost spread, purely on rate.
- Four levers close the gap — prompt caching (~90% off cache reads), batch processing (~50% off), volume discounts, and model routing — but the prerequisite for all of them is visibility into where the money actually goes.
The Gap Is Structural, Not a Billing Bug
Think of an LLM pricing page like a restaurant menu. The prices look reasonable until you realize the listed price is for the starter. The main course (output tokens) costs three to five times more. Then there are surcharges for the premium seating (long context), a service fee for the chef's prep work you can't see (reasoning tokens), and somehow the kitchen has been running your tab even during your Saturday morning prep session (non-production environments).
Your bill in production rarely equals input_tokens × input_rate. Providers quote input because it is the smaller number. Production traffic pays for output, hidden reasoning tokens, repeated prefixes, non-prod replay traffic, and context tiers you crossed without noticing.
Teams budget from the pricing page and get surprised at invoice time. That surprise is predictable once you map the five multipliers below. The multipliers stack — fixing one while ignoring the others leaves most of the gap intact.
The five hidden multipliers behind the gap between the sticker price and the invoice.
Hidden Multiplier #1: Output Tokens Cost 3–5× More Than Input
Every provider leads with their input token rate because it's the smaller number. The actual workhorse of cost is output tokens — the tokens the model generates — which are priced 3 to 5 times higher.
Claude Sonnet 4.6 lists $3.00 per million input tokens and $15.00 per million output tokens. DigitalOcean Serverless Inference lists the same split at the time of writing. For a typical conversational application at a 1:2 input-to-output ratio, your effective blended cost is already 3× the advertised input rate before any other multiplier applies.
This is the primary driver behind the 50–90% overpayment pattern. Teams budget from the input number on the pricing page and are surprised when actual bills reflect the heavier output reality.
What to check: Pull your actual input-to-output token ratio from the last 30 days. If output runs 2× or 3× input volume, your effective rate is nowhere near the number on the pricing page.
Hidden Multiplier #2: Reasoning Tokens Bill as Output and Stay Invisible
Models with extended thinking or chain-of-thought reasoning — Claude adaptive thinking, OpenAI o3 and o4-mini — generate "thinking tokens" as part of their response. These are the model's internal reasoning steps. They never appear in what your user sees.
They are billed at full output token rates.
Think of it like hiring a consultant who charges by the hour. You asked for a one-page memo and it took 15 minutes to write — but they also charge for the 3 hours they spent researching, deliberating, and drafting before they put a single word on paper. The memo looks the same. The invoice doesn't.
On Claude Opus 4.8 at $25/M output tokens, a response with 500 visible output tokens and 2,000 thinking tokens costs 5× more than the same response without extended thinking. Your user saw 500 tokens of response. You paid for 2,500.
This is not a flaw — thinking tokens unlock substantially better performance on complex reasoning tasks. But if you've enabled extended thinking without bounding how hard the model thinks, you may be paying for far more deliberation than your use case requires.
On current frontier models the control has changed shape. Claude Opus 4.8 and Opus 4.7 require adaptive thinking — they no longer accept a fixed budget_tokens cap, and you tune depth with the effort parameter (low → max) instead. A fixed token ceiling isn't the knob anymore; matching effort to task complexity is.
{
"model": "claude-opus-4-8",
"max_tokens": 16000,
"thinking": { "type": "adaptive" },
"output_config": { "effort": "low" },
"messages": [{ "role": "user", "content": "Classify this support ticket." }]
}
jsonThis request sends a short classification prompt to Claude Opus 4.8 with adaptive thinking enabled, but sets effort to low so the model spends fewer hidden reasoning tokens before answering. Opus 4.8 always thinks; you cannot turn that off, but you can match depth to the task. A ticket label does not need the same reasoning budget as a multi-step agent workflow. Pairing low effort with a simple prompt keeps invisible thinking tokens from inflating a bill that should stay near the visible output count.
What to check: Review whether extended thinking is enabled on your deployments, and whether depth is bounded to the task. Inspect usage on every response — reasoning models routinely dominate spend on trivial tasks when effort defaults high.
Hidden Multiplier #3: Non-Production Traffic Shares One API Account
Here's an analogy that tends to land with engineering leads: imagine a coffee shop that charges you every time someone practices making your order — not just when they hand it to you. Every espresso the barista pulled during training, every drink remade during a test, every batch produced for a team tasting session before the café opened — all billed to your tab.
That's roughly what happens when your LLM API account doesn't distinguish between production and non-production usage.
CI pipelines replay the same test scenarios on every pull request. Developers run flows locally while iterating on prompts. Staging environments replicate production traffic for validation. Load tests hammer the model endpoint to verify the application — not the model — can scale. Without environment tags, all of it bills like production.
Speedscale's analysis of enterprise AI deployments documents the pattern: most teams don't notice how much of their AI bill comes from non-production environments until the number is already painful. A mid-size support center running 10,000 tickets per day on Claude Sonnet will generate a predictable production spend. Add CI pipelines, developer testing, and staging validation — and the true bill can be 2–3× what you'd calculate from production traffic alone.
What to check: Tag your API calls by environment (production, staging, CI, local) so your dashboard can group spend by where it came from. First-time environment splits often put CI and staging at 30–50% of total token volume.
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["MODEL_ACCESS_KEY"],
base_url="https://inference.do-ai.run/v1",
)
response = client.chat.completions.create(
model="anthropic-claude-4.6-sonnet",
messages=[{"role": "user", "content": "Summarize this log line."}],
extra_body={
"metadata": {
"environment": os.environ.get("APP_ENV", "local"),
"service": "ci-test-runner",
}
},
)
print(response.usage)
pythonThis snippet calls DigitalOcean Serverless Inference through the OpenAI-compatible SDK and attaches metadata tags for environment and service on every request. Those tags ride in extra_body so you can slice usage logs by source — CI runners, staging, production — instead of treating every token as prod spend. Printing response.usage gives you the token counts to reconcile against your bill once tagged traffic is grouped.
Hidden Multiplier #4: Verbosity Varies 2–4× by Model for the Same Prompt
Claude tends toward thoroughness. o4-mini tends toward brevity. For the same prompt, the output token count can vary by 2–4× depending on which model you're using. You pay for every output token either way.
It helps to see model selection as moving cost through two separate channels: the rate channel (the per-token price a model charges — multiplier #1) and the volume channel (how many output tokens it produces for the same task — this one). They compound: send a chatty model a job at a premium per-token rate and you overpay on both axes at once. Later we'll isolate each channel with real measurements.
The analogy here is email length. Ask a detail-oriented colleague to confirm a meeting time and you might get three paragraphs of context, alternatives, and caveats. Ask a concise one and you get "Tuesday at 2pm works." Both answers contain the same information. One costs considerably more to produce.
At scale, this matters. If you're using Claude Sonnet for a task where a label or a yes/no decision is all you need, and the model returns a well-reasoned explanation every time, you're paying for thousands of tokens that provide no value to your application.
The short-term fix is prompt engineering rather than model switching: explicit constraints like "respond with the label only, no explanation" cut output 60–80% on structured tasks. Long term, match model verbosity to task type and measure output tokens per endpoint, not per model catalog entry.
Hidden Multiplier #5: Long-Context Surcharges Apply to the Whole Request
International data roaming works like this: your carrier shows you a reasonable per-MB rate, everything seems fine, and then you cross a border without realizing it. Suddenly the same activity costs 4× more — applied retroactively to the entire session, not just the traffic beyond the threshold.
LLM long-context pricing works the same way.
GPT-5.5 (per OpenAI's model documentation) is priced at $5/M input and $30/M output below 272K input tokens. Above 272K input tokens, pricing shifts to $10/M input and $45/M output — applied to the entire session, not just the tokens above the threshold.
Gemini 3.1 Pro Preview (per Google's pricing docs) charges $2.00/M input and $12.00/M output up to 200K context. Above 200K, the rate jumps to $4.00/M input and $18.00/M output — and critically, all tokens in that request (input and output) are billed at the long-context rate, not just the tokens over the threshold.
| Model | Standard rate (input / output per M) | Threshold | Long-context behavior |
|---|---|---|---|
| GPT-5.5 | $5 / $30 | >272K input | 2× input / 1.5× output, full session |
| Gemini 3.1 Pro Preview | $2 / $12 | >200K input | $4 / $18 per M, whole request |
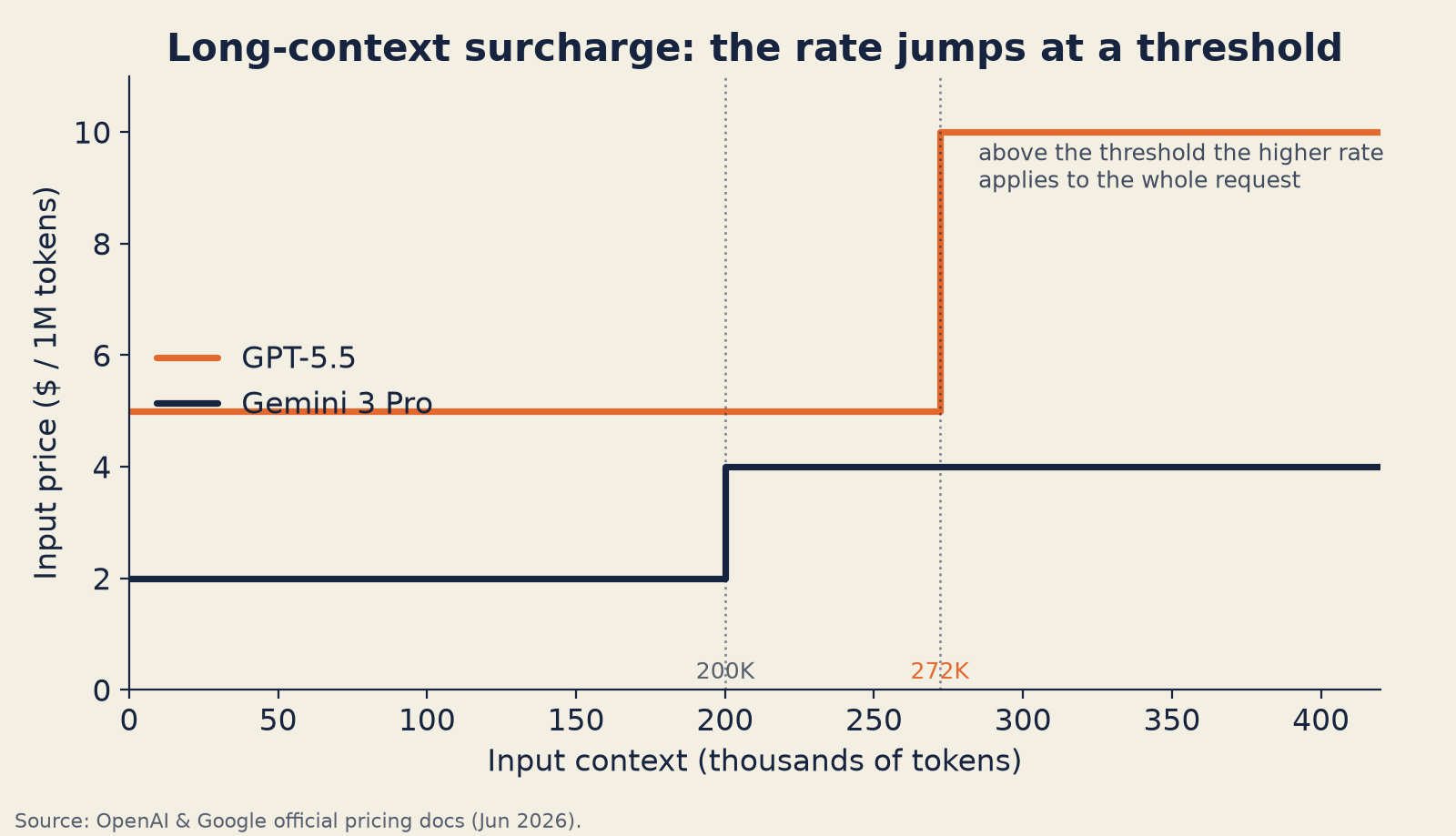
Cross a provider's context threshold and the higher rate applies to the entire request — not only the tokens past the line.
RAG pipelines stuffing large document chunks into context, and multi-turn agents running reasoning across long conversation histories, cross these thresholds on a meaningful share of requests. If you haven't audited your context lengths against provider surcharge thresholds, you may be paying double on a lot of traffic without knowing it.
What to check: Audit your p95 and p99 input context length against each provider's tier boundary. If those numbers are approaching any threshold, understand exactly what percentage of requests is getting billed at long-context rates.
What We Measured on DigitalOcean Serverless Inference
The multipliers above are provider-agnostic. The numbers in this section come from live API runs on https://inference.do-ai.run/v1 documented in DigitalOcean's Multi-Model API Cost Governance with the Inference Router tutorial (as of June 16, 2026). Methodology: fixed prompts, temperature=0, token counts read from response usage, costs computed from published DigitalOcean Inference rates at the time of the run. (Full disclosure applies here — I work at DigitalOcean — but these are documented API measurements, not marketing claims, and the underlying pattern reproduces on any provider.)
The model-selection tax: identical tokens, 36× cost spread. Model choice moves cost through two separate channels: the per-token rate the model charges, and the output volume it produces (verbosity, multiplier #4). This first measurement isolates the rate channel. Same classification prompt, three models, identical token shape (94 input / 80 output) — output ratio and verbosity are held constant, so the only variable is price:
| Model | Per-request cost (June 16, 2026 run) | vs cheapest path |
|---|---|---|
openai-gpt-oss-20b | $0.00004070 | baseline |
openai-gpt-5 | $0.00091750 | 22.5× |
anthropic-claude-4.6-sonnet | $0.00148200 | 36× |
Calculation for openai-gpt-oss-20b: (94 × $0.05 + 80 × $0.45) / 1,000,000 = $0.00004070.
Sending every classify call to Sonnet when openai-gpt-oss-20b clears the accuracy bar is a 36× per-request tax — paid purely on rate, before verbosity adds anything. At 700,000 classify requests per month, that gap is $28.49 vs $1,037.40 on routing alone. No volume discount fixes model mismatch.
This aligns with the broader DigitalOcean benchmark in Metrics that Matter with Serverless Inference: cost per completed answer swings roughly 230× across the model catalog on the same provider. Provider list price moves cost by percents. Model choice moves it by orders of magnitude.
Reasoning output volume: ~840× the classify cost. Same provider, different task, June 16 live runs:
| Path | Model | Tokens (in / out) | Per-request cost |
|---|---|---|---|
| Classify | openai-gpt-oss-20b | 94 / 80 | $0.00004070 |
| Customer Q&A | anthropic-claude-4.6-sonnet | 412 / 292 | $0.00445200 |
| Reasoning | openai-gpt-5 | 891 / 3,411 | $0.03417625 |
The reasoning path costs ~840× more per request than classify ($0.03417625 vs $0.00004070). GPT-5's input rate ($1.25/M) is lower than Sonnet's ($3.00/M), so this is not a rate-channel effect — the bill explodes because reasoning generates 3,411 output tokens vs 80 on classify. That's multiplier #2 and the volume channel of multiplier #1 in numeric form: output volume, including thinking tokens billed before the visible answer, dominates the cost.
Reproduce the measurement. Run this against your own Model Access Key. It logs the usage block you need for cost attribution:
curl -s -X POST "https://inference.do-ai.run/v1/chat/completions" \
-H "Authorization: Bearer $MODEL_ACCESS_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "openai-gpt-oss-20b",
"temperature": 0,
"messages": [
{"role": "system", "content": "Classify the ticket. Reply with one word: billing, bug, how-to, or account."},
{"role": "user", "content": "I was charged twice for my subscription last month."}
]
}' | python3 -c "import sys,json; u=json.load(sys.stdin)['usage']; print(u)"
bashThis one-liner posts a fixed classify prompt to openai-gpt-oss-20b with temperature=0 and prints the response usage block, so you see the exact prompt_tokens and completion_tokens you're billed against. Repeat the same call with anthropic-claude-4.6-sonnet on the identical prompt, and the usage delta is the model-selection tax your bill carries today: same task shape, different per-token rate.
Full router setup, task policies, and the x-model-router-selected-route response header are documented in the Inference Router how-to.
Visibility Comes Before Optimization
The common thread across all five hidden multipliers is that they're invisible by default. Most LLM API billing dashboards show total token counts and total spend. They omit:
- Tokens by environment (production vs. non-prod)
- Cache hit rate and missed savings
- Thinking tokens vs. visible output token split
- Long-context surcharge exposure by request
- Per-task-type output token distribution
Without that breakdown, you optimize blind. Building this visibility is a one-time investment that pays back continuously. Every optimization in this article starts with "what to check" — and none of those checks are possible without instrumented observability on your inference layer.
A blunt starting point: estimate blended cost straight from the usage counters your API already returns, using DigitalOcean/Anthropic list rates. Wire it to your inference logs:
#!/usr/bin/env python3
"""Estimate blended LLM cost from token usage counters."""
from dataclasses import dataclass
@dataclass
class ModelRates:
input_per_m: float
output_per_m: float
cache_read_per_m: float = 0.0
RATES = {
"anthropic-claude-4.6-sonnet": ModelRates(3.00, 15.00, 0.30),
"openai-gpt-oss-20b": ModelRates(0.05, 0.45),
}
def estimate_cost(model, input_tokens, output_tokens, cache_read_tokens=0, thinking_tokens=0):
rates = RATES[model]
billable_output = output_tokens + thinking_tokens
input_cost = (input_tokens / 1_000_000) * rates.input_per_m
cache_cost = (cache_read_tokens / 1_000_000) * rates.cache_read_per_m
output_cost = (billable_output / 1_000_000) * rates.output_per_m
total = input_cost + cache_cost + output_cost
headline = (input_tokens / 1_000_000) * rates.input_per_m
return {
"total_usd": round(total, 4),
"input_only_usd": round(headline, 4),
"multiplier_vs_input_rate": round(total / headline, 2) if headline else 0.0,
}
# 1M input, 2M output, 500K thinking: multiplier ~13.5× vs input-only estimate
print(estimate_cost("anthropic-claude-4.6-sonnet", 1_000_000, 2_000_000, thinking_tokens=500_000))
pythonThis helper turns raw token counters into a dollar estimate that includes output and thinking tokens, not just input. The multiplier_vs_input_rate field surfaces the gap between pricing-page math and what you actually pay: the example at the bottom — 1M input, 2M output, 500K thinking — returns a multiplier of roughly 13.5× against an input-only estimate. Use it to flag endpoints where blended cost diverges from what you budgeted.
Four Levers, Ordered by Leverage
Assuming you're staying on managed APIs, here are the four levers with the highest return on optimization effort.
1. Prompt caching — cuts repeated prefix cost
Prompt caching reuses computed prefixes — your system prompt, few-shot examples, and RAG context template — across requests, eliminating the cost of re-processing the same tokens every call.
Think of it like a copier warm-up: the first copy takes a moment, but copies two through two thousand are instant and cheap. Anthropic cache reads bill at 10% of the base input rate (pricing docs) — a 90% discount. The cache write costs 1.25× for a 5-minute TTL and 2× for a 1-hour TTL, so you pay once to store the prefix and then save on every hit afterward. A 1M-token system prompt at an 80% cache hit rate changes input economics materially.
The mechanics of getting there — including the common single-field mistake that drops hit rates to single digits — are covered in Article 3 of this series and in DigitalOcean's Advanced Prompt Caching.
2. Batch / async processing — ~50% discount, no engineering required
For any workload that doesn't require a synchronous response — document processing, nightly analytics, bulk classification, evaluation runs — batch inference offers roughly 50% off with a 24-hour SLA. If your job tolerates delay and you still call sync endpoints, you are leaving the easiest discount on the table.
3. Volume discounts — ask for them
Negotiated discounts kick in at high monthly spend. Many teams who qualify never ask. The conversation is worth having.
4. Model routing — the largest lever when traffic mixes task types
The biggest single lever is routing simple requests to smaller, cheaper models. Claude Haiku 4.5 costs $1.00/M input; Claude Sonnet 4.6 costs $3.00/M — a 3× price difference, and the gap widens to 10×+ if a capable open-weight model clears your accuracy floor. That's the 36× per-request tax from the measurements above, viewed from the fix side: for tasks where the smaller model produces equivalent quality (classification, summarization, FAQ responses from retrieved context), running Sonnet is waste.
The challenge is operationalizing this routing without maintaining custom routing logic. Inference Router automates task-to-model dispatch on inference.do-ai.run without application-side routing logic. In DigitalOcean's cost governance runs, routing a 700K / 250K / 50K classify / Q&A / reasoning traffic mix through the router reduced monthly cost 39.6% vs a Sonnet-only baseline and 63.7% vs Opus-only — using the same per-request measurements above. The architecture for doing this without building it yourself is covered in Article 5 of this series.
Why Per-Token Billing and Routing Map to the Multipliers
This article has been intentionally provider-neutral because the patterns apply across every LLM API provider. That said: these problems are partly architectural, and the billing and routing mechanics map onto the multipliers one by one.
Multiplier #3 (non-prod leakage) is an observability problem. Per-token billing on a shared API key does not separate environments by default. You fix it with tags in request metadata and a dashboard that groups usage by environment. DigitalOcean Serverless Inference bills from the same usage block the API returns, so your log pipeline and your invoice share one source of truth.
Model selection drives multiplier #4 (verbosity) and the rate spread together, and both are architecture problems. When one frontier model serves classify and reasoning, you pay frontier prices on one-word labels through two channels at once: the higher per-token rate (the measured 36× classify premium) and, for chattier models, higher output volume on the same task.
The Inference Router sends each request to the model best suited to the task. For how it works under the hood, see the Inference Router architecture deep-dive.
Routing by task complexity keeps average cost proportional to task value. Classify traffic stays on openai-gpt-oss-20b. Q&A stays on Sonnet with session pinning for KV-cache warmth. Reasoning escalates to GPT-5 only when output volume justifies the rate. That architecture directly attacks multipliers #1, #2, and #4. It does not replace environment tagging for multiplier #3.
For hosting mode tradeoffs — when per-token serverless yields to GPU-hour dedicated — see Serverless vs Dedicated vs Batch Inference and Dedicated vs Serverless Inference as You Scale.
But regardless of which platform you're on, the prerequisite is the same: know your actual cost anatomy. Teams that have visibility into token-type breakdown, environment tagging, cache hit rate, and context length distribution consistently find substantial savings — not from clever tricks, but from finally seeing where the money goes.
Summary: The Five Hidden Multipliers
The gap between the price on the website and what you actually pay comes from five compounding factors:
- Output tokens cost 3–5× more than input tokens — and most production workloads are output-heavy
- Reasoning/thinking tokens are billed at full output rates and invisible in the response
- Non-production environments — CI, staging, local testing — roll into the same bill and routinely exceed expectations
- Output verbosity varies 2–4× by model — untamed verbosity is cost without quality
- Long-context surcharges double or quadruple per-token rates at thresholds most teams have never checked against their p95 context lengths
The four levers to close the gap: prompt caching, batch processing for async workloads, volume discounts, and model routing. In the June 2026 DigitalOcean runs, routing alone moved a realistic traffic mix 39.6% below a Sonnet-only baseline.
The prerequisite for all of it is visibility. Without per-environment tagging, cache hit rate monitoring, and per-task-type token breakdowns, you're navigating blind — and flying blind is exactly how a $200 bill becomes a $6,000 surprise.
This is Article 1 in a 5-part series on LLM inference in production. Article 2 covers model selection methodology. Article 3 covers prompt caching in practice. Article 4 examines total cost of ownership for a full AI stack. Article 5 covers multi-provider routing architecture.
References
- Multi-Model API Cost Governance with the Inference Router — DigitalOcean (June 2026 live runs)
- Metrics that Matter with Serverless Inference — DigitalOcean (cost-per-answer benchmarks)
- Why Serverless Inference Consistency Varies on the Same Model — DigitalOcean (TTFT testing)
- Anthropic API Pricing — Anthropic
- DigitalOcean Inference Pricing — DigitalOcean
- GPT-5.5 Model Documentation — OpenAI
- Gemini API Pricing — Google
- I Analyzed 60+ LLM Models and Found Companies Overpay by 50-90% — DEV Community
- The Hidden AI Bill: Why Non-Prod LLM Costs Spiral — Speedscale
- Inference Router: An Architecture Deep-Dive — DigitalOcean


